
Red Hat blog
A cluster upgrade is something that every OpenShift Container Platform (OCP) customer will do as a maintenance process for their platforms. OCP is rapidly changing and there are many new features customers are already demanding that will come with the new versions.
The OCP product upgrade process is really straightforward and doesn’t take much time, depending on your cluster size. It can also be customized to meet additional requirements.
The following procedure has been tested during a Red Hat engagement for one of our customers, who required zero downtime for their running apps on OCP during the upgrade process. A PoC was performed for this, where we tested the automated in-place upgrade and a custom upgrade. In both cases, we upgraded the platform from OSE v3.2 to OCP 3.3, and we used a simple PHP application deployed in HA mode as a reference.
Cluster Details
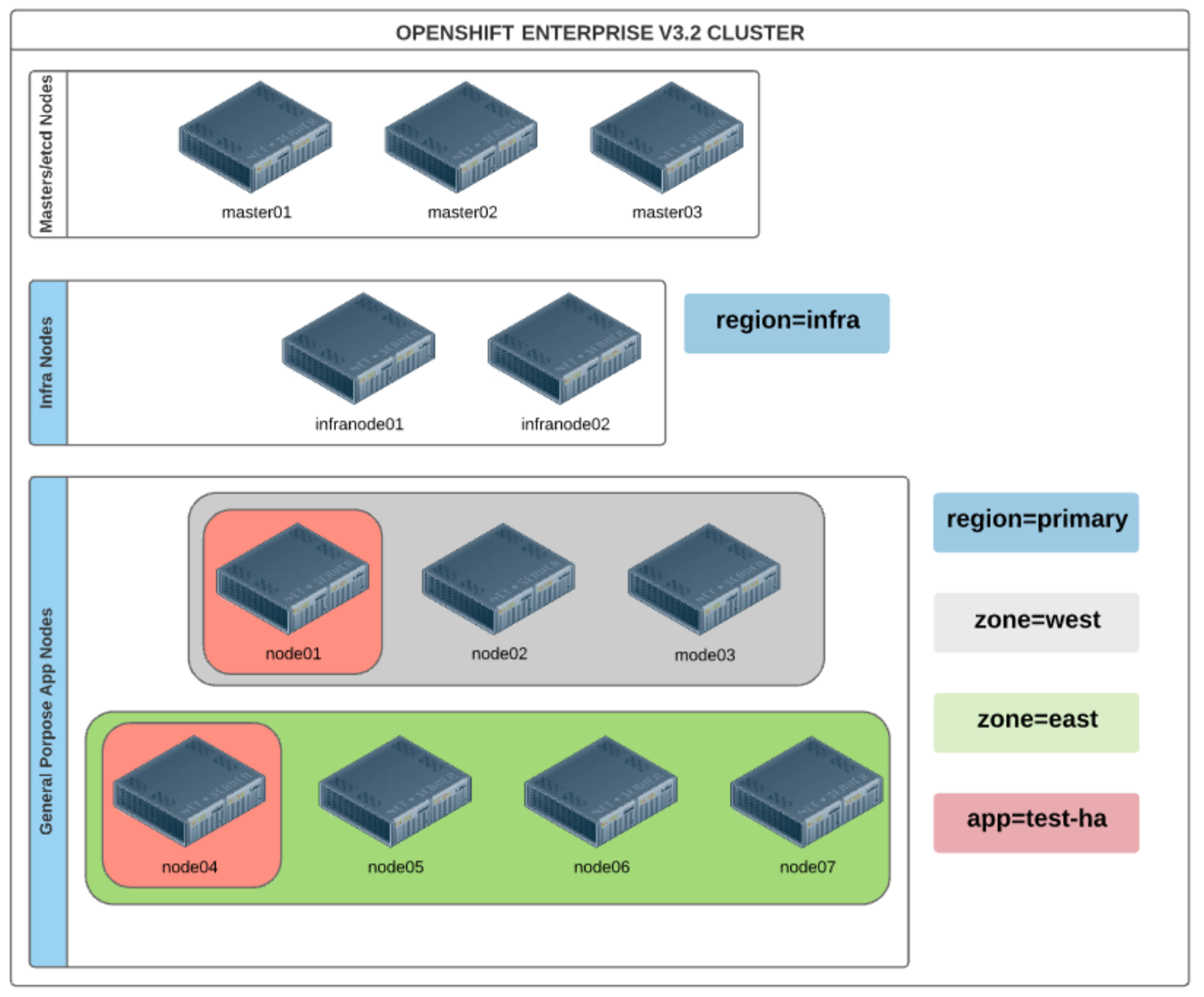
These are the cluster details architecture used for the PoC. Load balancing for both the Master API and router pods was externally provided by an HAProxy service.

{kind=link}
There were two router pods running, one on each Infra Node (label region: infra), and there were 2 application Pods running, 1 on each App Node (label app: test-ha), to give HA capability to the deployed application.
In-place Upgrade
The automated in-place upgrade process resulted in 250 seconds downtime. Many state changes were identified in the resultant monitoring log.
Starting 3.2 to 3.3 Upgrade
...
HTTP OK: HTTP/1.1 200 OK - 65101 bytes in 0.149 second response time |time=0.148878s;;;0.000000 size=65101B;;;0
HTTP OK: HTTP/1.1 200 OK - 65103 bytes in 0.113 second response time |time=0.113369s;;;0.000000 size=65103B;;;0
CRITICAL - Socket timeout after 10 seconds
HTTP CRITICAL: HTTP/1.0 503 Service Unavailable - pattern not found - 193 bytes in 0.015 second response time |time=0.015391s;;;0.000000 size=193B;;;0
HTTP CRITICAL: HTTP/1.0 503 Service Unavailable - pattern not found - 193 bytes in 0.015 second response time |time=0.015020s;;;0.000000 size=193B;;;0
HTTP CRITICAL: HTTP/1.0 503 Service Unavailable - pattern not found - 193 bytes in 0.009 second response time |time=0.009148s;;;0.000000 size=193B;;;0
HTTP CRITICAL: HTTP/1.0 503 Service Unavailable - pattern not found - 193 bytes in 0.006 second response time |time=0.005796s;;;0.000000 size=193B;;;0
HTTP CRITICAL: HTTP/1.0 503 Service Unavailable - pattern not found - 193 bytes in 0.014 second response time |time=0.013831s;;;0.000000 size=193B;;;0
HTTP CRITICAL: HTTP/1.0 503 Service Unavailable - pattern not found - 193 bytes in 0.056 second response time |time=0.056075s;;;0.000000 size=193B;;;0
HTTP OK: HTTP/1.1 200 OK - 64652 bytes in 7.497 second response time |time=7.497118s;;;0.000000 size=64652B;;;0
HTTP OK: HTTP/1.1 200 OK - 64838 bytes in 0.371 second response time |time=0.370671s;;;0.000000 size=64838B;;;0
…
…
HTTP OK: HTTP/1.1 200 OK - 65122 bytes in 0.370 second response time |time=0.370430s;;;0.000000 size=65122B;;;0
HTTP OK: HTTP/1.1 200 OK - 65103 bytes in 0.181 second response time |time=0.181499s;;;0.000000 size=65103B;;;0
HTTP CRITICAL: HTTP/1.0 503 Service Unavailable - pattern not found - 212 bytes in 0.006 second response time |time=0.006409s;;;0.000000 size=212B;;;0
HTTP CRITICAL: HTTP/1.0 503 Service Unavailable - pattern not found - 212 bytes in 0.026 second response time |time=0.026379s;;;0.000000 size=212B;;;0
HTTP CRITICAL: HTTP/1.0 503 Service Unavailable - pattern not found - 212 bytes in 0.003 second response time |time=0.003359s;;;0.000000 size=212B;;;0
HTTP CRITICAL: HTTP/1.0 503 Service Unavailable - pattern not found - 212 bytes in 0.004 second response time |time=0.003891s;;;0.000000 size=212B;;;0
...
…
…
HTTP OK: HTTP/1.1 200 OK - 65105 bytes in 0.258 second response time |time=0.257821s;;;0.000000 size=65105B;;;0
HTTP OK: HTTP/1.1 200 OK - 65112 bytes in 0.417 second response time |time=0.416958s;;;0.000000 size=65112B;;;0
…
Finishing 3.2 to 3.3 Upgrade
Custom Upgrade
The custom upgrade process we designed splits up the process into three different steps. In each step we updated the following components:
- Step 1: Upgrade Master and etcd nodes
- Step 2: Upgrade Nodes labeled as ‘zone: west’ and one Infra Node
- Step 3: Upgrade Nodes labeled as ‘zone: east’ and one Infra Node
This process takes more time than the automated in-place process (which has only one step), but it ensures no application downtime. This approach could be used for every OpenShift cluster upgrade, but cluster/application-specific considerations must be reviewed for any particular deployment to ensure the results are as expected. There are different options that could be applied to this process, like combining step 1 and 2, or changing the order in which the pods are evacuated. One of the most important bits of this procedure is the load balancing mechanism, so the process could be different depending on the software (F5, AWS ELB, HAProxy, etc.) used for this purpose.
This is the Ansible inventory we used during the process, which we split up into three different parts, starting with ‘step 1’ and adding the next step on every Ansible Playbook iteration, step 1, step 2 and step 3.
[masters]
master01.ha.test openshift_hostname=master01.ha.test openshift_public_hostname=master01.ha.test
master02.ha.test openshift_hostname=master02.ha.test openshift_public_hostname=master02.ha.test
master03.ha.test openshift_hostname=master03.ha.test openshift_public_hostname=master03.ha.test
[etcd]
master01.ha.test openshift_hostname=master01.ha.test openshift_public_hostname=master01.ha.test
master02.ha.test openshift_hostname=master02.ha.test openshift_public_hostname=master02.ha.test
master03.ha.test openshift_hostname=master03.ha.test openshift_public_hostname=master03.ha.test
[nodes]
master01.ha.test openshift_hostname=master01.ha.test openshift_public_hostname=master01.ha.test openshift_node_labels="{'region': 'infra', 'zone': 'default'}" openshift_schedulable=false
master02.ha.test openshift_hostname=master02.ha.test openshift_public_hostname=master02.ha.test openshift_node_labels="{'region': 'infra', 'zone': 'default'}" openshift_schedulable=false
master03.ha.test openshift_hostname=master03.ha.test openshift_public_hostname=master03.ha.test openshift_node_labels="{'region': 'infra', 'zone': 'default'}" openshift_schedulable=false
node01.ha.test openshift_node_labels="{'region': 'primary', 'zone': 'east'}" openshift_hostname=node01.ha.test openshift_public_hostname=node01.ha.test
node02.ha.test openshift_node_labels="{'region': 'primary', 'zone': 'east'}" openshift_hostname=node02.ha.test openshift_public_hostname=node02.ha.test
node03.ha.test openshift_node_labels="{'region': 'primary', 'zone': 'east'}" openshift_hostname=node03.ha.test openshift_public_hostname=node03.ha.test
node04.ha.test openshift_node_labels="{'region': 'primary', 'zone': 'west'}" openshift_hostname=node04.ha.test openshift_public_hostname=node04.ha.test
node05.ha.test openshift_node_labels="{'region': 'primary', 'zone': 'west'}" openshift_hostname=node05.ha.test openshift_public_hostname=node05.ha.test
node06.ha.test openshift_node_labels="{'region': 'primary', 'zone': 'west'}" openshift_hostname=node06.ha.test openshift_public_hostname=node06.ha.test
node07.ha.test openshift_node_labels="{'region': 'primary', 'zone': 'west'}" openshift_hostname=node07.ha.test openshift_public_hostname=node07.ha.test
infranode01.ha.test openshift_node_labels="{'region': 'infra', 'zone': 'east'}" openshift_hostname=infranode01.ha.test openshift_public_hostname=infranode01.ha.test
infranode02.ha.test openshift_node_labels="{'region': 'infra', 'zone': 'west'}" openshift_hostname=infranode02.ha.test openshift_public_hostname=infranode02.ha.test
During the full process, there are two manual interventions that we need to take care of before step 2 and 3. It consists of evacuating application pods running on nodes that are going to be upgraded to ensure they are not affected during the upgrade process. This can be achieved in two different ways, either using the evacuating option available on OCP or manually disabling the application probe for that particular node from your LB software.
Following this, we achieved the desired 100% Application availability during our upgrade PoC from OSE v3.2 to OCP 3.3.
Starting OCP Upgrade v3.2 to v3.3 Process
…
HTTP OK: HTTP/1.1 200 OK - 65093 bytes in 0.292 second response time |time=0.292266s;;;0.000000 size=65093B;;;0
HTTP OK: HTTP/1.1 200 OK - 65093 bytes in 0.151 second response time |time=0.150627s;;;0.000000 size=65093B;;;0
HTTP OK: HTTP/1.1 200 OK - 65094 bytes in 0.112 second response time |time=0.111930s;;;0.000000 size=65094B;;;0
...
Masters/Etcd upgrade Done
…
HTTP OK: HTTP/1.1 200 OK - 65088 bytes in 0.131 second response time |time=0.131126s;;;0.000000 size=65088B;;;0
HTTP OK: HTTP/1.1 200 OK - 65092 bytes in 0.105 second response time |time=0.104927s;;;0.000000 size=65092B;;;0
HTTP OK: HTTP/1.1 200 OK - 65096 bytes in 0.332 second response time |time=0.332448s;;;0.000000 size=65096B;;;0
...
Upgrade east Nodes
…
HTTP OK: HTTP/1.1 200 OK - 65090 bytes in 0.169 second response time |time=0.168614s;;;0.000000 size=65090B;;;0
HTTP OK: HTTP/1.1 200 OK - 65104 bytes in 0.395 second response time |time=0.394547s;;;0.000000 size=65104B;;;0
HTTP OK: HTTP/1.1 200 OK - 65092 bytes in 0.122 second response time |time=0.121854s;;;0.000000 size=65092B;;;0
...
Upgrade east Nodes Done
…
HTTP OK: HTTP/1.1 200 OK - 65101 bytes in 1.235 second response time |time=1.234629s;;;0.000000 size=65101B;;;0
HTTP OK: HTTP/1.1 200 OK - 65091 bytes in 0.342 second response time |time=0.341738s;;;0.000000 size=65091B;;;0
HTTP OK: HTTP/1.1 200 OK - 65109 bytes in 0.883 second response time |time=0.883466s;;;0.000000 size=65109B;;;0
...
Upgrade west Nodes
…
HTTP OK: HTTP/1.1 200 OK - 65103 bytes in 0.481 second response time |time=0.481191s;;;0.000000 size=65103B;;;0
HTTP OK: HTTP/1.1 200 OK - 65092 bytes in 0.201 second response time |time=0.200664s;;;0.000000 size=65092B;;;0
HTTP OK: HTTP/1.1 200 OK - 65098 bytes in 0.287 second response time |time=0.286553s;;;0.000000 size=65098B;;;0
...
Upgrade west Nodes Done