
The Red Hat Performance Team, along with our partners Solarflare and Supermicro, have been working together to leverage the latest technologies and features in the container orchestration space to demonstrate that it is possible to containerize extreme low-latency applications without any degradation in performance. The team used the well-known STAC-N1™ benchmark from STAC® (the Securities Technology Analysis Center), to prove out the technology.
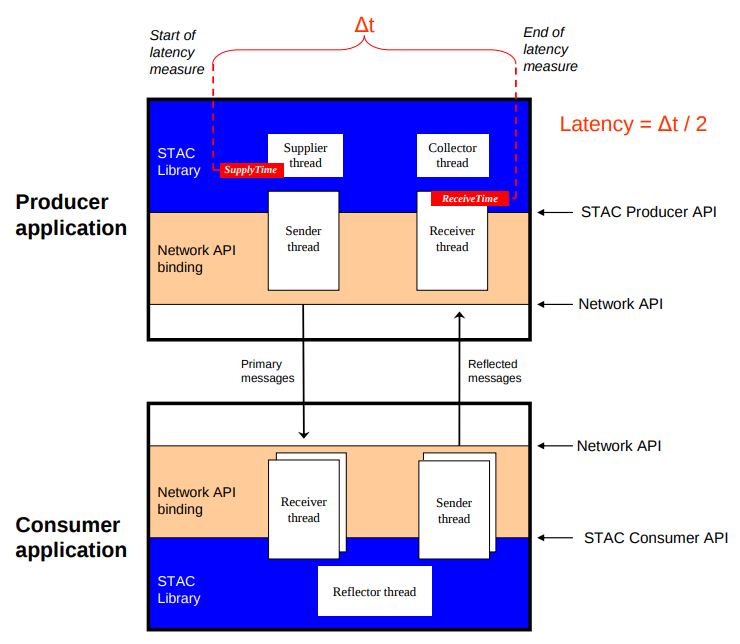
STAC-N1 is a financial services-focused benchmark which focuses on how quickly applications in the trade flow (algorithmic "black boxes", matching engines, smart order routers, etc.) can get information from and to the network. The STAC-N1 benchmark suite measures the performance of network stacks under a simulated market data environment using a convenient, software-only test harness.
Executive Summary and Key Take-aways
Several world records were achieved by the Bare Metal test variant, including lowest mean latency @ both base and maximum message rates; with OpenShift achieving the same result.
The team ran two scenarios: Bare Metal, and containerized (using OpenShift 3.10, base on Kubernetes 1.10).
Here are the reports and precise configuration disclosures for both configurations:
- Bare Metal: https://stacresearch.com/SFC180604a
- OpenShift: https://stacresearch.com/SFC180604b
The Bare Metal configuration achieved the following world records:
- Compared to all publicly disclosed STAC-N1 results to date, this system demonstrated the lowest mean latency for 264-byte messages at both the base rate of 100K messages per second and the highest rate tested of 1 million messages per second.
- Max latency at 100K messages per second was the lowest of any system usin
 g sockets.
g sockets.

In the OpenShift configuration, mean and 99th percentile latency for this configuration were the same as those of the same system running as bare metal, at both the base rate of 100K messages per second and the highest rate tested of 1 million messages per second.
The STAC-N1 benchmark is produced by the STAC Network I/O Special Interest Group, a group of end-user organizations and vendors with an interest in the performance of host network stacks, including hardware and software. Click here for a more in-depth overview.
Ground Work
Red Hat believes that Kubernetes and containers are the future of application development. We’re fully invested in its upstream development, overall health and in shaping its future. Because of this philosophy, we took an upstream-first approach to solving for the requirements of performance-sensitive applications.
For more information on that philosophy, check out our blog post Performance-sensitive workload? There’s an application platform for that: It’s called Kubernetes from November 2017.
The STAC-N1 benchmark has traditionally focused on bare metal deployment scenarios. That meant our effort to re-platform N1 into OpenShift (Red Hat’s conformant, enterprise Kubernetes distribution) had to begin with discovery work to see exactly what features we had to build into Kubernetes to run a containerized N1 benchmark.
Having participated in the STAC Network I/O SIG for several years, we know that STAC-N1 requires the following:
- HugePages (for Solarflare driver memory)
- Direct access to a network device from userspace
- De-jittered cores
As of OpenShift 3.10, all three features upstream features are fully supported by Red Hat:
- HugePages
- Device Manager (support extends to the Kubernetes API only. Vendors support the device plugin itself)
- CPU Manager
We worked with the upstream community to establish the Resource Management Working Group which advocates for and designs features to support a workload like STAC-N1.
The working group introduced alpha support for HugePages in the Kubernetes 1.8 cycle. HugePages are a very common optimization technique for Java, C, and other applications with very large memory requirements. In the STAC-N1 scenario, we allocated 400 HugePages for use by the Solarflare network driver on the same NUMA node where the NICs are installed.
We approached kernel bypass networking by inventing Device Plugins (with GPUs as the initial use-case). To prove out that work, in the fall of 2017, Red Hat worked with NVIDIA to leverage the NVIDIA Device Plugin when running another STAC-A2™ (risk computation) benchmark on Kubernetes 1.8.
Along with Solarflare, Red Hat authored a device plugin for Solarflare network adapters, making it possible to inject OpenOnload-accelerated traffic into a pod on OpenShift. Using the sfnt-pingpong tool from Solarflare to compare bare metal versus OpenShift, we found the performance numbers to be impressive, and gave us confidence that the foundational performance of the systems was ready to introduce STAC-N1. Read on for how to deploy sfnt-pingpong on OpenShift.
Using Device Plugins for other use cases is being actively researched and prototyped by the community, including the Kubernetes Network Plumbing Working group.
On to the STAC-N1 benchmark...
What's "new" in this result? For starters, the first ever STAC-N1 on Kubernetes/OpenShift...but so much more:
- Brand new Supermicro Hyper-Speed Latency-optimized, overclocked servers (including optimized BIOS)
- Brand new Solarflare XtremeScale X2522 NICs, first STAC-N1 published on these adapters
- Latest Red Hat Enterprise Linux 7.5, first STAC-N1 published on this OS
- Newest version of OpenOnload 201805, first STAC-N1 published on this version
- Newest (pre-release) version of OpenShift Container Platform
- Invented new Solarflare Kubernetes Device Plugin
- Created a prestart hook to ease use of OpenOnload accelerated containers
All supporting the groundbreaking, forward looking R&D that used cutting-edge parts and bits to introduce cloud-native application design and agility to capital markets.
The following graph is subset of the public Bare Metal report indicating mean, 99% and 99.9% latencies across a variety of message rates (all 264 byte UDP). Thanks to the mix of new hardware, software and extensive tuning effort, a mean latency of 2.3 microseconds @ 1 million messages per second was achieved while running the benchmark on Bare Metal. The X-axis is message rate and the Y-axis is microseconds, and lower is better.

Here is the configuration of the benchmark environment for the OpenShift configuration:

To handle de-jittering of cores for use by the benchmark, we took a two-phase approach:
- Use the cpu-partitioning tuned profile. This profile aggressively de-jitters cores by partitioning the set of available cores into sets of housekeeping, and isolated cores, disables the CFS rebalance algorithm, and eliminates power management. Here we found an interesting gap that needs to be worked upstream: the kubelet (the kubernetes “node-agent” that runs on each node), does not account for system-level tuning related to isolated cores. As of now, it will schedule pods to run on cores that the kernel has isolated, which overrides some of the affinity settings implemented by tuned. This behavior necessitated the second phase of CPU tuning:
- Automation script to clean up the rest. For example:
- Disabling unnecessary services
- Removing unneeded kernel modules
- Dealing with IRQ affinity
- Removing any iptables rules
- Ensuring affinity for OpenShift processes.
The STAC-N1 configuration specifies exactly which cores to run producer and consumer threads on. Because of this, the CPU Manager feature (implemented by Intel, in the context of the Resource Management Working Group) in Kubernetes was not used.
STAC auditors logged into the environment to conduct the tests. The following graph is subset of the public OpenShift report indicating mean, 99% and 99.9% latencies across a variety of message rates (all 264 byte UDP). Thanks to the mix of new hardware, software and extensive tuning effort, a mean latency of 2.3 microseconds @ 1 million messages per second was achieved while running the benchmark on OpenShift. The X-axis is message rate and the Y-axis is microseconds, and lower is better.

OpenOnload-accelerated Pod Example Deployment
While membership in the STAC consortia is required for access to the STAC-N1 benchmark, let's walk through how to deploy and benchmark a simple latency test utility from Solarflare called sfnt-pingpong. Rather than bury the lede, here is a graph from our lab, of the p99 network latencies between two physical systems. Red bars are bare metal, and blue bars are the exact same systems, but running sfnt-pingpong in pods running on OpenShift 3.10. The X-axis is packet size, the Y-axis is microseconds, and lower is better.

Next, here is a graph of the maximum latencies. You can see that in this scenario, OpenShift is often within 1-2 microseconds of bare metal performance. As with the previous graph, the X-axis is packet size, the Y-axis is microseconds, and lower is better.

Let's pick up deployment of the utility assuming that the servers (particularly the BIOS) as well as the OS are tuned for optimal performance, and the Solarflare driver is installed on certain bare metal systems within the OpenShift Cluster.
Here is a logical diagram of a typical OpenShift cluster, with highly-available control plane and some pool of compute nodes. A few of those compute nodes, indicated by the snowflakes, are "special". These are the nodes we want our deployment to be scheduled to - the performance-optimized Supermicro servers, Solarflare NICs and Red Hat Enterprise Linux.

To start, create a new project to host the accelerated pods
<span># oc new-project solarflare</span>
Clone the Solarflare Device Plugin and Prestart Hook repositories:
# git clone https://github.com/solarflarecommunications/sfc-k8s-device-plugin
# git clone https://github.com/solarflarecommunications/sfc-k8s-prestart-hook
Build the prestart hook:
cd sfc-k8s-prestart-hook
Build the Solarflare Device Plugin container image
# cd sfc-k8s-device-plugin/container
# docker build -t sfc-dev-plugin .
Tag and push the built image to a registry
# docker tag sfc-dev-plugin quay.io/<username>/sfc-dev-plugin
# docker push quay.io/<username>/sfc-dev-plugin
Create the Security Context Constraints within the Solarflare namespace that will allow the device plugin the necessary privileges and capabilities to do its job.
<span># oc create -f scc/sfc-deviceplugin-scc.yaml</span>
Now we’re ready to create the DaemonSet that will run the Solarflare Device Plugin pod on every node.
<span># oc create -f deviceplugin/sfc-device-plugin.yml</span>
Verify that the DaemonSet and associated pods are running:
# oc get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
sfc-device-plugin 2 2 2 2 2 beta.kubernetes.io/arch=amd64 25m
# oc get pods
NAME READY STATUS RESTARTS AGE
sfc-device-plugin-r6bzt 1/1 Running 0 25m
sfc-device-plugin-ff43t 1/1 Running 0 25m
If all is well, the plugin will have updated the Capacity and Allocatable fields on each node to include the discovered Solarflare hardware devices (in this case it is two, because the card has two ports).
# oc describe node server1.example.com | grep -A 13 Capacity:
Capacity:
cpu: 24
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 65691072Ki
pods: 250
solarflare.com/sfc: 2
Allocatable:
cpu: 24
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 65588672Ki
pods: 250
solarflare.com/sfc: 2
These new fields are what make it possible for users to request Solarflare hardware in their pod specification. The Kubernetes scheduler will find a node with an available Solarflare device, and schedule the pod to that node. From that point the Kubelet (the node agent) is responsible for starting the pod with the device available to it.

Next, let's use those devices. Deploy 2 test pods that consume Solarflare NICs
<span># oc create -f examples/onload-deployment.yaml</span>
Ensure they’ve been scheduled to 2 nodes
# oc get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
onload-deployment-644b4d85b-9pw44 1/1 Running 0 4m 172.17.0.2 server1.example.com
onload-deployment-644b4d85b-px2gw 1/1 Running 0 4m 172.17.0.4 server2.example.com
Run sfnt-pingpong between them
<span># oc exec onload-deployment-644b4d85b-px2gw onload --profile=latency-best sfnt-pingpong</span>
<span># oc exec onload-deployment-644b4d85b-9pw44 onload --profile=latency-best sfnt-pingpong udp 192.168.0.200</span>
(where 192.168.0.200 is the IP assigned to the Solarflare NIC on the bare metal host (i.e. by /etc/sysconfig/network-scripts/ifcfg-xyz). Handling multiple interfaces is a hot topic in the Kubernetes upstream. Red Hat is working with the community and our partners to eventually make this a reality.
Here is the output of the sfnt-pingpong test. The latency numbers are in nanoseconds (i.e. in the first row. the mean latency is 1,107 nanoseconds).
size mean min median max %ile stddev iter
0 1107 1055 1108 6873 1140 19 1000000
1 1112 1066 1113 8280 1143 19 1000000
2 1107 1058 1108 6065 1138 17 1000000
4 1112 1065 1113 5682 1143 16 1000000
8 1113 1066 1114 6267 1144 17 1000000
16 1114 1066 1114 5364 1144 16 1000000
32 1155 1116 1154 5856 1186 17 1000000
64 1186 1141 1185 5623 1218 16 1000000
128 1305 1255 1305 5788 1339 18 1000000
256 1441 1390 1441 6073 1476 19 1000000
512 1776 1732 1775 6445 1807 19 840000
1024 2354 2313 2353 7107 2386 19 635000
<snip>
While there is still work to do both upstream and in product to smooth things out, this demonstration should give you a sense of how to deploy OpenOnload accelerated containers on OpenShift. We'd love to hear more about your experiences integrating real applications according to this guide!
Summary
It’s our belief that Linux containers and container orchestration engines, most notably Kubernetes, are positioned to power the future of enterprise applications across industries. Along the way, challenges to this perception are bubbling up. In the area of performance-sensitive workloads, like portfolio risk analysis and other financial transactions where a matter of microseconds can mean the difference between success and failure, there are strong concerns. This is why Red Hat has embarked on a mission to enable Red Hat OpenShift as a performance-sensitive application platform (P-SAP) to better support these critical workloads.
Working with Solarflare and Supermicro, we continue working towards our goal of onboarding performance-sensitive applications on to OpenShift, demonstrating a successful pairing of bare metal performance with container orchestration.
While the STAC-N1 benchmark is important, and the results can be found in the links below, we believe this effort can have an impact beyond financial services. Artificial intelligence, machine learning, high performance computing, and big data, to name a few areas, are all examples of workloads where the set of Performance-Sensitive Application Platform features are critical. Drawing from this experience with the Kubernetes community and STAC, we’re hoping to be able to drive OpenShift forward as the application platform for workloads on public, private and hybrid cloud, offering a common development and deployment plane for all applications, regardless of industry, type or performance sensitive nature.
View the reports and precise configuration disclosure:
Bare Metal: https://stacresearch.com/SFC180604a
OpenShift: https://stacresearch.com/SFC180604b
Learn More
- Meet with Red Hat engineers at the STAC Summit in New York City on June 13th, where we will present The Path to Cloud-Native Trading Platforms at 3:35pm in the main ballroom.
- Join us for an OpenShift Commons presentation of this content on July 12th.
- You can also reach out to me on Twitter @jeremyeder, I'd love to hear your feedback on this blog!
STAC and all STAC names are trademarks or registered trademarks of the Securities Technology Analysis Center, LLC.
About the author

A 20+ year tech industry veteran, Jeremy is a Distinguished Engineer within the Red Hat OpenShift AI product group, building Red Hat's AI/ML and open source strategy. His role involves working with engineering and product leaders across the company to devise a strategy that will deliver a sustainable open source, enterprise software business around artificial intelligence and machine learning.
More like this
Browse by channel

Automation
The latest on IT automation that spans tech, teams, and environments

Artificial intelligence
Explore the platforms and partners building a faster path for AI

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
Explore how we reduce risks across environments and technologies

Edge computing
Updates on the solutions that simplify infrastructure at the edge

Infrastructure
Stay up to date on the world’s leading enterprise Linux platform

Applications
The latest on our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Developer resources
- Customer support
- Red Hat value calculator
- Red Hat Ecosystem Catalog
- Find a partner
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit