
This is a guest blog by Vick Kelkar from Portworx. Vick is a Product person at Portworx. With over 15 years in the technology and software industry, Vick’s focus is on developing new data infrastructure products for platforms like PCF, PKS, Docker, and Kubernetes.
Kubernetes adoption initially was powered by stateless applications. As the project matured, Kubernetes introduced the StatefulSet object so that applications can run with persistent data in a cloud native manner. As stateful applications, like PostgreSQL, started running on Kubernetes clusters, the need to easily manage complex deployments became clear. The built-in Kubernetes constructs did not allow for more complex install, upgrade or management of Kubernetes resources which resulted in a person doing manual post install deployment tasks.
To solve this problem, the CoreOS team (now part of Red Hat) launched the Operator Framework project. The idea of an Operator is to introduce a custom controller and custom resource into Kubernetes cluster which understands the life cycle of a stateful application. At Portworx, we decided to adopt the Operator Framework in order to embed domain-specific knowledge into our CustomResource called StorageCluster and introduced a new Kubernetes object to make maintenance and management of Portworx platform easier.
What is the Portworx Data Platform?
Portworx platform is a cloud-native storage and data management platform for containerized workloads running on Kubernetes platforms like Red Hat OpenShift. Portworx platform is designed to provide dynamic storage provisioning, high availability and disaster recovery for multi-cluster, multi-cloud workloads. The Portworx Data Platform offers these features:
- Optimized persistent volumes for container workloads
- High availability across nodes, racks, and availability zones
- Multi-cloud disaster recovery
- Container-level or cluster-wide volume encryption
- Container Storage Interface (CSI) based implementation
- Multi-cluster and multi-cloud application migrations
- Application consistent snapshots
Why use OpenShift for your Kubernetes applications?
There are many posts on the web that describe how to assemble your own Kubernetes distribution. Even though it is a good learning exercise to compose your own Kubernetes cluster, it can distract you from your organization’s main mission. OpenShift is a distribution based on Kubernetes with full-stack automated operations to manage hybrid cloud and multi cloud deployments, optimized for developer productivity. Some of the considerations for using OpenShift include:
- Easier full stack install, upgrades and lifecycle management experience
- Operator-based approach for internal components that automate maintenance
- Inclusion of new tools to empower developers like Service Mesh (currently in Technology Preview)
What does Portworx Enterprise Operator provide?
The main design goals of the Portworx Enterprise Operator was to efficiently manage the install and upgrade workflow of all components that make up the Portworx Data Platform. Another design goal of the Operator was to simplify complex deployment scenarios related to network interfaces, secret-stores and cloud drive configurations. We wanted to embed domain-specific knowledge into the Operator so that we could do smart upgrades and automatic scaling of the data platform. Finally, we wanted to improve observability of the data platform by exposing status in a Kubernetes-native manner.

Key Features of the Portworx Enterprise Operator:
- Install, upgrade and full lifecycle management of Portworx Data Platform components
- Introduction of StorageCluster CRD to manage Portworx cluster the Kubernetes way
- Provide sane defaults for deployments but allow for user-provided overwrites
- A custom controller to automate and manage complex maintenance tasks
Installing the Portworx Enterprise Operator on OpenShift
Using the openshift-install CLI and the base domain of openshift.portworx.com, we have installed a demo-vkelkar OpenShift cluster on AWS. You can find details of how to install OpenShift on AWS here.

We will now walk through steps needed to install the Portworx Enterprise Operator on the OpenShift Cluster.
- In the OpenShift cluster, navigate to OperatorHub and install the certified Portworx Enterprise Operator by clicking the install button.
-
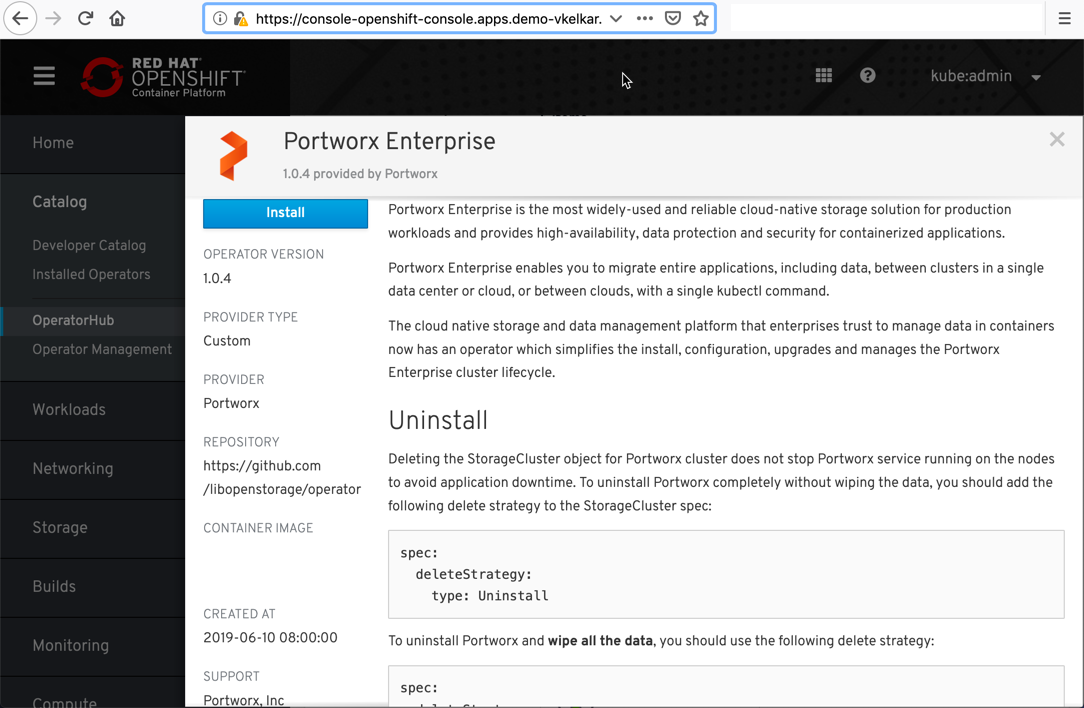

- Once the Portworx Enterprise Operator is installed, you will see the Portworx Enterprise Operator listed in the Installed Operators section.
-
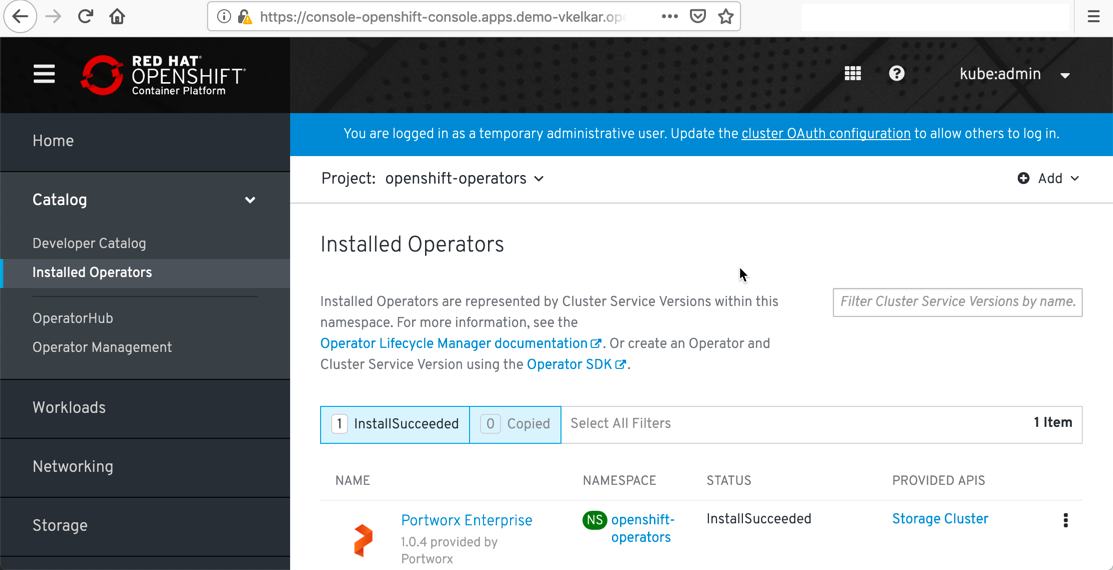
- After the Portworx Enterprise operator is installed, you can proceed to creating a Storage Cluster using the “Create New” in the Storage Cluster tile.


- We are going to add additional AWS cloud specific parameters called “CloudStorage/deviceSpecs” to our “Storage cluster” yaml since we are using gp2 drives in an AWS environment.

- Once the Portworx Enterprise Operator is installed and the Operator creates a StorageCluster instance, the installed footprint should look similar to the image below, for a 3 node StorageCluster deployment.

- Using the Portworx Enterprise built-in CLI, `pxctl` you can verify the status of the Portworx cluster by running the command in the Portworx pod’s terminal as shown in the image below.

What’s next?
The Portworx Enterprise Operator makes it easier to package, deploy and manage the Portworx Data Platform on a Kubernetes cluster. We plan to continue adding domain-specific knowledge and logic into our Operator. The Operator SDK and Portworx Enterprise Operator has allowed our customers to reduce deployment issues and increase maintainability.
The Portworx Enterprise Operator is available on OperatorHub.io and the Red Hat OpenShift Certified Portworx Enterprise Operator is available in Red Hat OpenShift 4’s Operator Hub. If you would like to experiment with our Portworx Enterprise Operator, please go to OperatorHub.io or contact a Portworx expert so that we can help you with your stateful applications and persistent storage needs.
Resources
- Learn more about Portworx Enterprise Operator at Operatorhub.io
- Learn more about the Operator Framework here
- Try OpenShift platform here
About the author

More like this
Browse by channel

Automation
The latest on IT automation that spans tech, teams, and environments

Artificial intelligence
Explore the platforms and partners building a faster path for AI

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
Explore how we reduce risks across environments and technologies

Edge computing
Updates on the solutions that simplify infrastructure at the edge

Infrastructure
Stay up to date on the world’s leading enterprise Linux platform

Applications
The latest on our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Developer resources
- Customer support
- Red Hat value calculator
- Red Hat Ecosystem Catalog
- Find a partner
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit