

Today I am pleased to announce the general availability of OpenShift Enterprise 3 by Red Hat. This major release of OpenShift Enterprise (OSE) was driven by the use of innovative open source technologies. Core to this release is the product's ability to leverage docker formatted containers and Kubernetes orchestration. This will enable users to run containerized JBoss Middleware, multiple programming languages, databases and other modern application runtimes at cloud scale. OpenShift Enterprise 3 offers a DevOps experience that enables developers to automate the application build and deployment process within a secure, enterprise-grade immutable application infrastructure.
The changes we made to the architecture in OpenShift Enterprise 3 allowed us to travel deep into the product and enhance the platform in significant ways. Many of our existing and new users will enjoy seeing these enhancements. People have been asking platform as a service (PaaS) vendors for more freedom to design their application architectures in a variety of ways. They wanted a more robust and openly extensible orchestration engine. They wanted a greater selection of application frameworks, databases, and runtimes. Lastly, they wanted a resilient, available, and secure experience for their deployed services. OpenShift Enterprise 3 delivers on these features and more. Here are a few of the release highlights that I believe will capture your attention.
Installation
OpenShift Enterprise 3 is one of the first Red Hat products to be released by Red Hat as a combination of traditional RPMs and docker images. Core components of the framework itself, like its routing layer and builder images, have been containerized. All of the application frameworks, databases, and runtimes have been released as docker formatted containers as well. These changes dramatically enhance the operational experience for the platform administrator.
<code>$ docker pull registry.access.redhat.com/openshift3_beta/ose-haproxy-router:latest</code>
Immutable Infrastructure
 One of the benefits of running in containers is the fact there is a separation of duty on the operating system. By making the decision to separate the user space from the kernel and then combining application code, runtimes and user space dependencies in immutable container images in the docker format, we open the door to working in concrete layers. What we have deployed to production, based on these immutable images, is what is in production and there is no way around it. What is in our code repository branch is in QA and we have a better way to connect code and application versions to deployments. These immutable building blocks are easier to work with and help to build larger services.
One of the benefits of running in containers is the fact there is a separation of duty on the operating system. By making the decision to separate the user space from the kernel and then combining application code, runtimes and user space dependencies in immutable container images in the docker format, we open the door to working in concrete layers. What we have deployed to production, based on these immutable images, is what is in production and there is no way around it. What is in our code repository branch is in QA and we have a better way to connect code and application versions to deployments. These immutable building blocks are easier to work with and help to build larger services.
OpenShift Enterprise 3 is completely transparent with its use of docker. It was a design goal of the platform to natively integrate docker and allow any docker compliant image to run on it without modification. It was a goal to not introduce any additional layers around those native APIs that would stand between the user and his image. This eliminates lock-in, allowing users to leave the OpenShift experience and leverage other 3rd party tools and solutions as needed. It insures customers are able to get the most out of the docker solution ecosystem.
Orchestration, Scheduling, and Declarative Management
OpenShift Enterprise 3 is taking full advantage of its Kubernetes core. Applications don't run in a single container and managing just one container is not as fun (or as easy) as managing thousands of them. Being able to make a docker formatted image anonymous to its infrastructure and intelligently link ports for application components to deliver a complex service topology, while still maintaining mobility across a large resource pool of CPU and memory, is one of the problems OpenShift helps solve through the use of Kubernetes pods. Targeting those resources based on decision logic that allows you to plug in custom facts allows OpenShift to offer users availability zones, dedicated infrastructure, or any other placement policy they want to execute through the Kubernetes scheduler. By combining the web scale architecture, intelligent orchestration of diverse application components and extensible scheduling of resources, Kubernetes drives OpenShift at the core to unlock efficiencies at scale.

More cattle and fewer pets. People want to be able to recover and replicate as quickly as possible. By leveraging the Kubernetes replication controller, OpenShift is able to give your application the assurance it needs to remain in production. In order to run a service on OpenShift, it has to have a health definition that defines how many pods/containers it requires and what their state should be. There are defaults, but the probe function is extensible to allow users to add additional tests. If a service fails to meet the health criteria, the Kubernetes replication controller will spin the application up on another part of the cluster. In a very declarative manner, users can voice how they want their application to look and the platform will insure it always looks exactly like that over the course of its life.
Application Frameworks and Runtimes
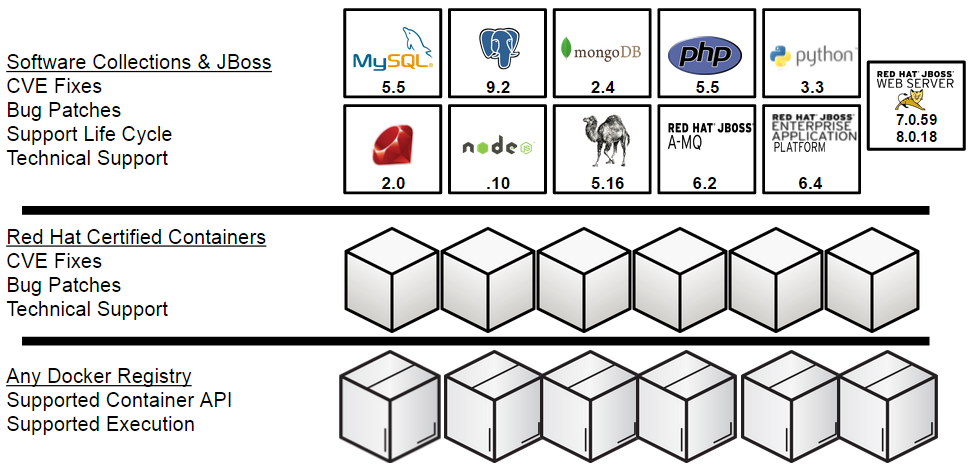
Platform as a Service lives and dies by the content it can provide to users. OpenShift Enterprise 3 provides MySQL, PostgresSQL, MongoDB, PHP, Python, Ruby, NodeJS, Perl, JBoss EAP, JBoss JWS (Tomcat), and JBoss A-MQ. But the platform does not stop there. Due to the way we designed our support for docker formatted containers, we have opened the platform up to being able to run one of the largest ecosystems of user provided content in the industry. People can pick and choose from where they would like to consume a large variety of application frameworks and runtimes. OpenShift has been able to take advantage of an established container community that many application ISVs have been a part of making successful.

Developer User Experience
We have found that by decomposing the application into more components (such as container, services, routes, builds, secrets, storage, etc) we are able to offer users more flexibility and the ability to create better applications. In OpenShift Enterprise 3 we make deploying templates or straight code from a git URL very easy. Developers can switch between their IDE environments and OpenShift with our first class support of OpenShift within the Eclipse plugin framework through JBoss Developer Studio. Check in code to git from the IDE and see the automated source to image process OpenShift provides as we take your code to production.

Developers have asked to see more about the underlining infrastructure they are on, what ports are in use, where are they linking, and other pieces of information that affect their application services. OpenShift Enterprise 3 provides a view of their service that contains relevant information, but not so much it becomes overwhelming.
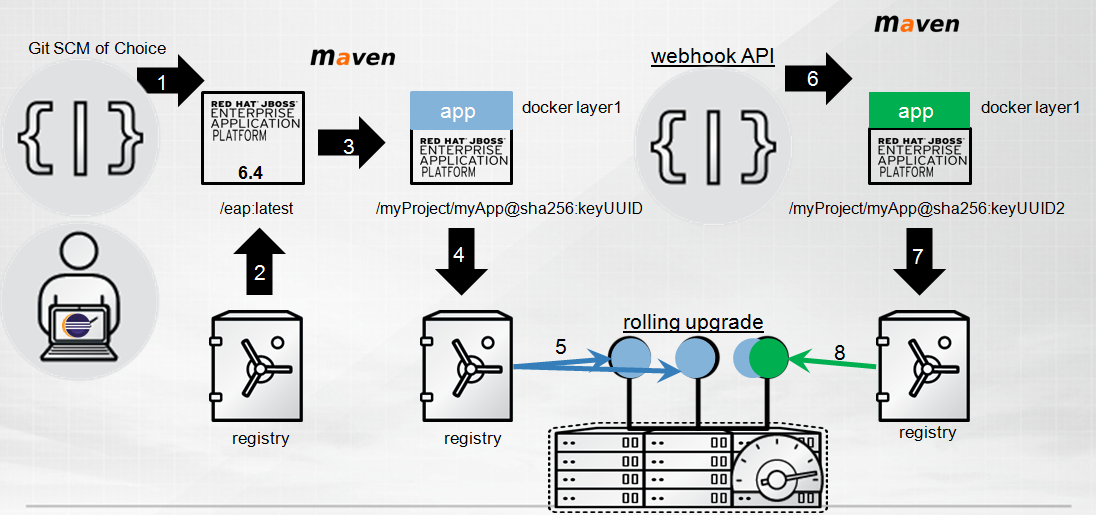
Developers do not need to become experts in docker or Kubernetes. With the innovative OpenShift source to image solution, OpenShift automates the build and deployment of applications so that developers can focus on their code while automating the image build process. Source to Image (S2I) allows operators to maintain the core or root of the application framework or runtime in a set of images, managed in OpenShift's integrated docker registry, while developer code changes and modifications are captured in new docker layers. This separation of duty is key and helps with platform ownership issues. OpenShift assembles the code into the docker layer with S2I builder instances to create updated docker images for deployment. The build is fully customizable to your build process. Let's look at an example with Java:

- The developer provides a git URL for his or her application and selects the version of application server they would like to use.
- OpenShift pulls the appropriate image out of the container registry and stands up an S2I builder.
- Following the prescribed assembly (i.e. you could have taken a binary instead of code), OpenShift builds the code with your maven configuration and creates a new docker layer on top of the root image that is owned by operations.
- OpenShift then places that layer into the registry for deployment
- Kubernetes identified the targetted node and deployed 3 instances of the application, clustered and horizontally scaled.
- The developer decided to change some code and issued a git commit from his or her IDE. OpenShift noticed through the webhook subscription.
- Based on policy choices made for the application, the process explained in steps 2-3 happens again. Some applications might not be configured to watch certain git branch changes. You have a lot of policy freedom. OpenShift then places that new layer back into the registry
- OpenShift then performs a rolling upgrade of the running application. It takes an instance out of the route and updates it. Only putting the instance back into the application route if it succeeds. Next OpenShift repeats the update with the next instance and then the next.
Networking
We have paid lots of attention to how services flow across the platform. PaaS needed better interfaces into the IaaS layer around networking and now we have it. Through an innovative use of software defined networking (SDN), OpenShift is now capable of delivering real IP services to applications. By automating the deployment and administration of OpenvSwitch and dynamically creating OpenFlow rules based on the need of the services, we have created a more application centric view of the IP address topology. This layer of the product is pluggable for those with existing investments in SDN solutions and we have some great partners, whom are industry leaders in this area, excited about the opportunity to deliver container networking integrations.
The platforms allows people to consolidate applications and get the most out of their resources. As more and more containers are deployed, the need for overlay networking practices become more and more important. OpenShift's ability to help automate those practices is critical. Plus, due to the fact OpenShift is allocating IP services for every container, network administrators can leverage existing firewall and monitoring solutions instead of getting confused with vhost redirects. Customers can decide to terminate SSL at the router or carry that encryption all the way down to the container on the node.
Routing
We have been able to evolve the platform routing solution in a few clever ways. We decided to stay with HAProxy for our default routing tier, only this time we have placed it in a container and allowed it to be scaled up by the platform. This cluster of HAProxy instances serves as a highly available routing tier for the entire platform (spanning all Nodes and containers), rather than running separate router instances per Node and multiple HAProxies for each application deployed. Having one routing layer helps us offer the users more control over their service routing while also allowing the platform administrator a more commonly deployed network routing solution, that will resemble more closely the solutions found in other parts of their datacenter. This makes replacing the OpenShift default router with existing specialized routing and load balancing solutions even easier.

Logging and Metrics
OpenShift Enterprise 3 offers an easy to use command line that automates the ability for a user to see standard error/out, execute a command for output, or tail a file remotely on a container. This stream of information from their container to their laptop is great when troubleshooting application issues. Platform administrators have the ability to aggregate those logs and integrate them into a larger log management solution. Since OpenShift 3 leverages standard IP through an overlay network, many existing monitoring solutions are easily applied to the platform. Kubernetes provides many interfaces around cAdvisor and an evolving heapster project that allows platform administrators to see usage information of the cluster. There are a number of open source project capitalizing on those interfaces. A great one is the ManageIQ project.
State for Application Services
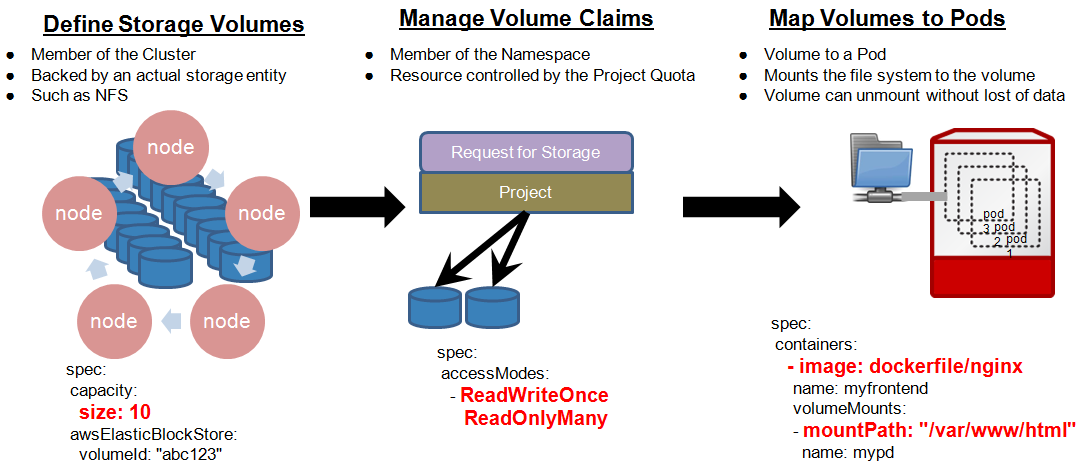
OpenShift has always been a thought leader in the the PaaS industry when it came to dealing with a mixture of stateful and stateless application services. OpenShift version 2 allowed users to choose to store information within their gear container. This meant they would have to backup and restore that information as they would else where in their datacenter and depending on the application, have a variety of operational procedures. Standard datacenter practices. In OpenShift 3 we decided to attack the problem at its core, leveraging Kubernetes storage volumes. Much like in the case of networking, we noticed a better way of interfacing with IaaS services around remote storage was needed. This time around, stateful applications will store their information to remote persistent storage mapped to each container.

Users enter into OpenShift and establish projects. These projects are what groups of developers can scrum around and deploy their applications and services. Projects maintain the storage quota for the group. Users can request persistent storage volumes from the platform and decide to mount that storage into their application containers based on any mount point. Our solution is smart enough to be able to move that storage mount around the cluster if the container is ever redeployed, so that if the application containers move for maintenance or scaling reasons, so do the connected storage volumes.
Application Architectures
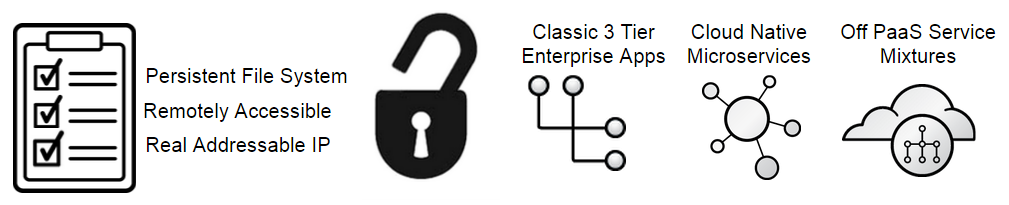
We've heard customers state that PaaS is too opinionated about how applications should be designed. OpenShift Enterprise 3 ends the era of the opinionated PaaS and makes every service a first-class citizen. By leveraging the core technologies above, OpenShift is allowing you to experience the most out of cloud native microservices while at the same time offering you an easier path to running existing or traditional application services. Users have a choice around which of the three design models fits the application and the operational staff for that application. Deploy a database service by itself. Deploy non HTTP/S services. By taking advantage of our container host implementation, routing, and Kubernetes we have given you back your freedom.

Security and Patching
 New technology can come with concerns over security and life cycle control. OpenShift Enterprise 3 offers some key features that will help answer those concerns. Platform administrators have policy control over how the platform behaves. Administrators can disallow any user from being able to start a privileged container on the platform. They control the UID ranges that containers are executing processes under. They control which users have the right to work with deployed imagestreams. Administrators can control what projects are allowed to deploy services to specific availability zones. Through policy, OpenShift can help tame the cluster and allow users to feel free under the administrator's regulation.
New technology can come with concerns over security and life cycle control. OpenShift Enterprise 3 offers some key features that will help answer those concerns. Platform administrators have policy control over how the platform behaves. Administrators can disallow any user from being able to start a privileged container on the platform. They control the UID ranges that containers are executing processes under. They control which users have the right to work with deployed imagestreams. Administrators can control what projects are allowed to deploy services to specific availability zones. Through policy, OpenShift can help tame the cluster and allow users to feel free under the administrator's regulation.
Staying up to date with the latest CVE fixes and bug errata can be difficult in large enterprises. OpenShift Enterprise 3 helps with this problem as well. First, Red Hat offers the best way to obtain updates for the application frameworks and runtimes we provide. By leveraging the RHEL Software Collections and JBoss middleware, OpenShift is able to provide tremendous cost savings. We do not place the burden of creating a compliance method on platform administrators. We provided support and CVE fixes and bug updates through your subscription for everything we provide. Things have gotten even easier now that we are leveraging containers. Developers and operators can select which application services they want to automatically update when a new base image is found inside the container registry. Let's say there is a CVE against node.js runtime. OpenShift will know which applications are using the node.js root image. The administrator can decide which ones of those applications should be updated with the new fix. OpenShift will redeploy the application on the new base container image in a rolling manner. All the operator needs to do is get the new image from the vendor, place it in the registry, and set the desired update policy. The rest is automated by OpenShift.
In Closing
We have shared this path with many of you for a number of years. Open source projects can cause people to become as close as family. We are extremely proud of what we have accomplished together by reaching the OpenShift Enterprise 3 release milestone. We have solved many of the problems that weigh down PaaS solutions of yesterday. We hope you will take this solution and do something remarkable with your ideas to drive new innovations that touch people, changes industries, and forces the world to be a better place.
About the author

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
More like this
Browse by channel

Automation
The latest on IT automation that spans tech, teams, and environments

Artificial intelligence
Explore the platforms and partners building a faster path for AI

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
Explore how we reduce risks across environments and technologies

Edge computing
Updates on the solutions that simplify infrastructure at the edge

Infrastructure
Stay up to date on the world’s leading enterprise Linux platform

Applications
The latest on our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Developer resources
- Customer support
- Red Hat value calculator
- Red Hat Ecosystem Catalog
- Find a partner
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit