
There has been a lot of buzz around the Serverless trend lately; what it really means and what are its merits. At the end of the day it’s really just a new way to treat certain workloads - background jobs. How does this new pattern fit in the context of developing cloud native applications and operating container platforms such as Red Hat OpenShift?
Laying the foundation
Delivering continuous innovation to customers often leads to continuous pressure on the developers to build and ship software... well, continuously. Smart companies are doing all they can to empower their development teams with the right culture to encourage productivity, and the right tools to make it happen. Emerging as the foundational layer for many organizations’ application development efforts is a container application platform, with OpenShift as a leading choice.
As infrastructure resources continue to be commoditized, and as services continue to be exposed as APIs, having a foundational layer is critical to bring everything together. This is especially important when dealing with multiple distributed applications and multiple distributed teams, as containerized applications, workloads, and services need a unifying environment.
Primed for a deeper integration
Iron.io has been a long time partner of Red Hat and OpenShift, with both its products, IronMQ and IronWorker, available in the OpenShift Hub. We were early adopters of container technologies, and the recent introduction of Hybrid Iron.io makes it easy to integrate with container-based platforms such as OpenShift through an independently deployable runtime service.
With the introduction of OpenShift Primed by Red Hat, customers who wish to enable the container-based job processing capabilities that Iron.io provides, can do so with the confidence that the solution is validated and works well in any OpenShift environment, public or private.
Running Iron.io with OpenShift
Getting started with Iron.io on OpenShift is easy. The following instructions walk through a simple example. To learn more about the process and to get started yourself, Contact Us.
1. Create OpenShift Application
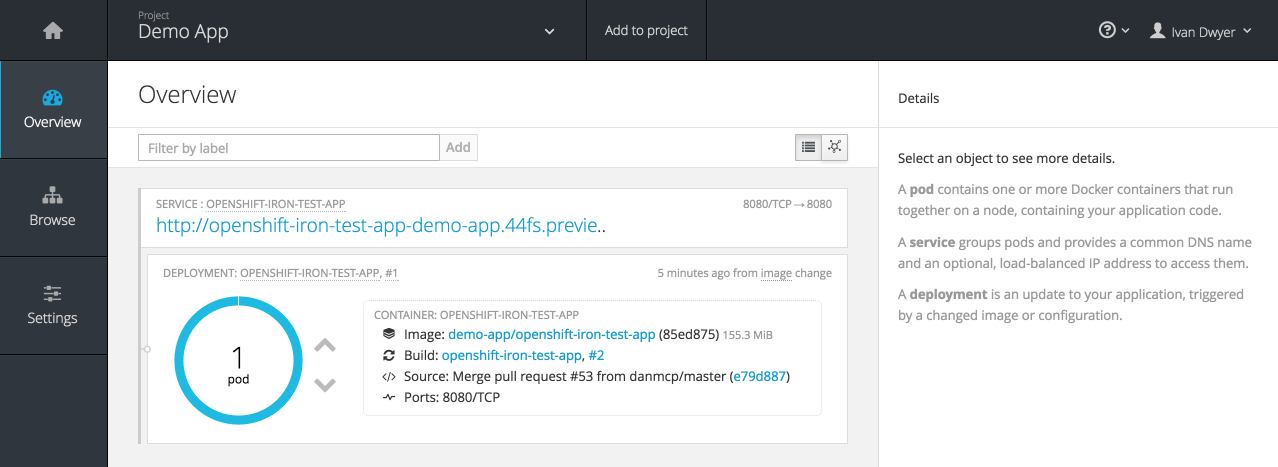
First create a project within OpenShift to setup the environment. For this demo, we’ll create a Ruby application with the sample code available from Red Hat.

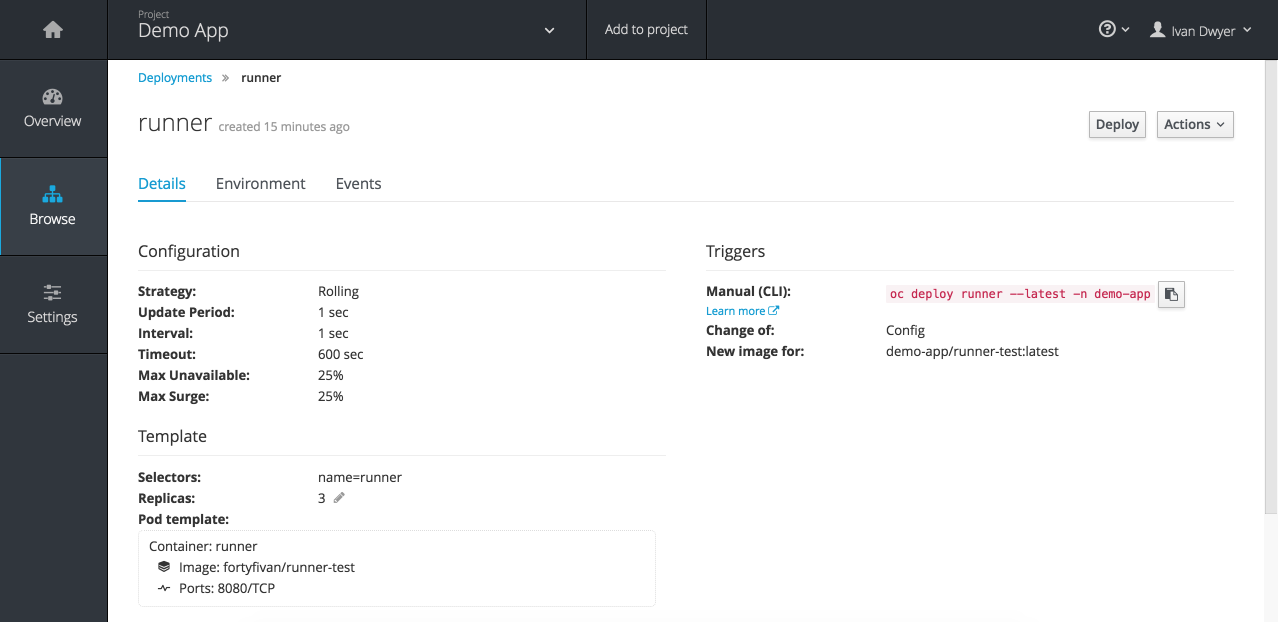
2. Create a Deployment Configuration
With Hybrid Iron.io, the runtime is an independent service available as an container image on Docker Hub (iron/runner is a private image at the time of writing this article while in beta). We refer to this as the “runner”, which is a service that monitors an IronMQ queue for new jobs. When a job is picked up, the runner grabs the associated Docker image, spins up a fresh container, executes the process, and tears down the container gracefully. Rinse and repeat at massive scale.
https://gist.github.com/fortyfivan/4fead12c65ba592bfff44a1babe3fe5b
With the deployment configuration created, it’s time to register with OpenShift.
$ oc create -f runner-deployment.yml
Before we run the deployment, we need to create an Iron.io cluster so we can set the right environment variables when starting the pod.
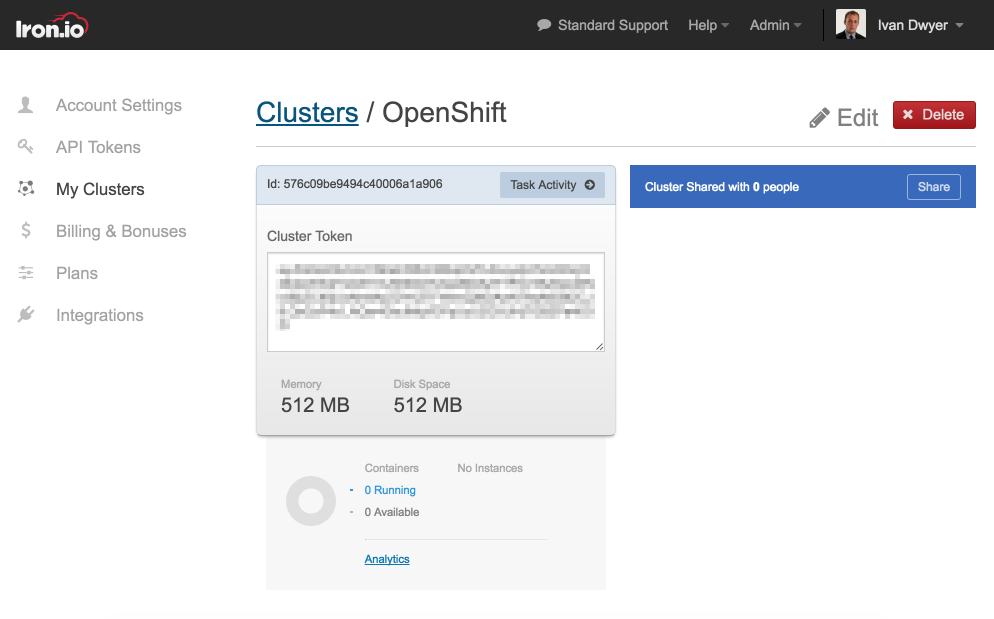
3. Create an Iron.io Cluster
If you don’t already have an Iron.io account, you can start a trial here. From the Iron.io Dashboard, you can easily create a cluster that provides you with an id and token value. Go to ‘Profile -> My Clusters -> New Cluster’. Give your new cluster a name, and then select Memory and CPU values, which are the resources to be allocated to each job. Once created, copy the id and token values as shown below.

4. Deploy the cluster
First, set the environment variables with the deployment configuration.
$ oc env deploymentconfigs runner CLUSTER_ID=%CLUSTER_ID$ oc env deploymentconfigs runner CLUSTER_TOKEN=%CLUSTER_TOKEN
The iron/runner image runs in privileged mode, which can be enabled for OpenShift by modifying the service account to ‘allowPrivilegedContainer: true’ as documented here.
Now we’re ready to deploy our Iron.io cluster using the OpenShift CLI.
$ oc deploy runner
This will create a pod with the number of runner containers from the ‘replicas’ as set in the deployment configuration. Iron.io scales based on the number of concurrent containers available to do work, which is a multiple of the replicas and the resource allocation.

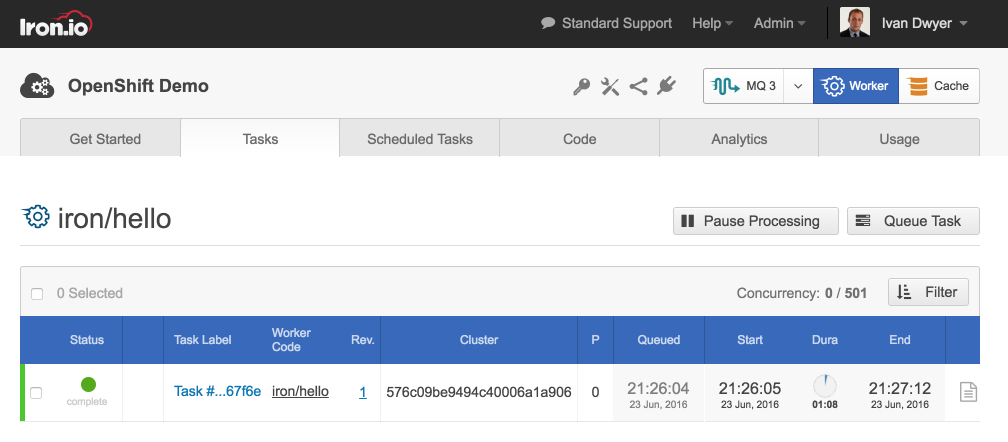
5. Queue tasks to your new cluster
Your cluster is now ready to do work. To send jobs to the runner pod for execution, all you need to do is use the cluster_id when using the Iron.io API.
First, register an image with Iron.io.
$ iron register iron/hello
Then queue up a job via CLI, or use one of our many client libraries in your language of choice. The cluster argument means that the job will be delivered to the cluster you create on OpenShift. Leaving that out means the job will run on the default public cluster operated by Iron.io.
$ iron worker queue --cluster %CLUSTER_ID iron/hello

Get Started Now!
As of today, beta users are being accepted for Iron.io on OpenShift. The pairing will provide users with an end-to-end environment for building and deploying applications at scale, without the headaches of complex operations. Flexible, abstracted platforms provide the best of both worlds, a sentiment shared by both Red Hat and Iron.io.
About the author

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Browse by channel

Automation
The latest on IT automation that spans tech, teams, and environments

Artificial intelligence
Explore the platforms and partners building a faster path for AI

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
Explore how we reduce risks across environments and technologies

Edge computing
Updates on the solutions that simplify infrastructure at the edge

Infrastructure
Stay up to date on the world’s leading enterprise Linux platform

Applications
The latest on our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Developer resources
- Customer support
- Red Hat value calculator
- Red Hat Ecosystem Catalog
- Find a partner
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit