
It seems like only yesterday that I found myself sitting in Boston at the Red Hat 2015 Summit surrounded by OpenShift customers writing about the release of OpenShift 3.0. In 5 short months, the community has reached another major milestone! Please allow me to introduce you to OpenShift 3.1.
Although the OpenShift 3.0 release delivered a ton of features, those features touched four main areas:
- Transformation to an open container format so that users could take full advantage of the docker eco-system while re-architecting around kubernetes, to allow for container orchestration and service management
- Containerization of MySQL, Postgres, MongoDB, Ruby, node.JS, Python, PHP, Perl, Tomcat, JBoss Enterprise Application Server, and JBoss A-MQ. But done so in a way that would allow people to give operations the freedom to control the maintenance of the base image in for bug and security fixes via automated rolling updates. This allows Red Hat to keep those images up to date for the customer, while allowing developers an ability to continuously introduce change into the immutable image layers. OpenShift source to image delivers this and more.
- Creation of an interaction layer that helps users develop and deploy services across an application life cycle.
- Platform integration to existing datacenter investments such as storage and routing solutions.
OpenShift 3.1 focuses on adding features to strengthen the developer experience. The release adds more capabilities for the mixing of mode1 and mode2 application designs. It improves platform awareness and insight. All while releasing more content for people to build larger, more production focused services. You are going to love these features. Let's dig in!
Developer Experience
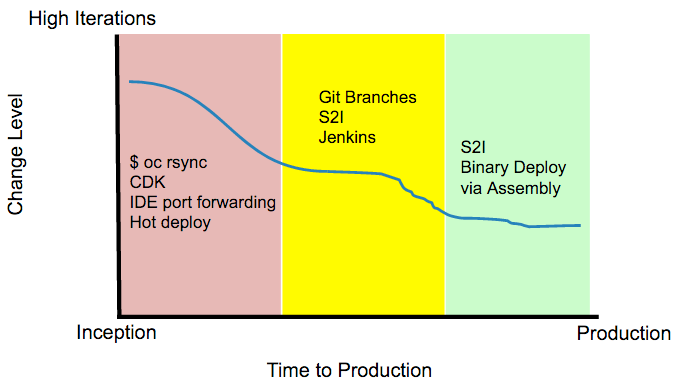
The biggest thing we learned over the last 5 months was the fact developers use a wide variety of tool chains depending on where they are in the application life cycle. At the point of inception, a brand new idea popped up in someone's head, it is common to see high code iterations. Most of these commits are exploratory in nature and therefore the time it takes to see the code change comes at a high cost. During these situations, we observe them doing a combination of 3 things:
- Move files and hot deploy their example application for idea testing and feedback loop closure.
- Work on their local workstation via docker images or similar virtualization techniques.
- Work from their IDE and port forward between their workstation and the deployed application.
In order to help enable the developer during this stage, we have created a new command called 'oc rsync' that leverages rsync or tar to move files from the workstation to the running docker container without invoking the source to docker image build process. This helps facilitate an ability to instantly test code ideas.
We enhanced the Eclipse IDE plugin to allow the developer to remain within their IDE and work with the platform.

Red Hat has also put together an excellent container developers kit (CDK) for people to use on their Windows or OS X based operating systems. Next month, we will be integrating the OpenShift vagrant image into that CDK experience. The CDK is designed for those developers that wish to author docker compliant containers and then deploy those docker images onto their corporate container application platform.
Users have always been able to drive OpenShift actions from their corporate Jenkins deployment. In this release, we offer the developer an ability to deploy a containerized Jenkins image into their project for their private or cross project use. This solution works nicely with an ability to automatically annotate docker layer deployments against git branch notation.
At the end of the day, OpenShift 3.1 offers a line of business an opportunity to leverage an assortment of developer integration points that can change from inception to production.

Developers have a new customizable content list to choose from within the interface.

From the improved web console, the developer can delete entire projects, stop/start services, rollback deployments, or cancel builds. We have also enabled mouse over status with warning badges over component icons to display event information.

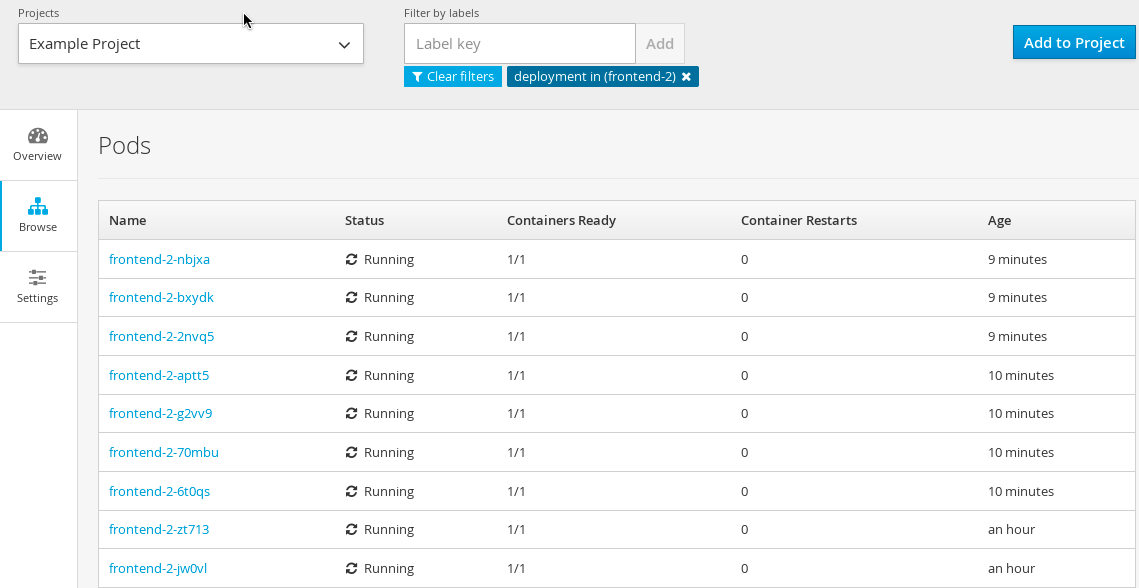
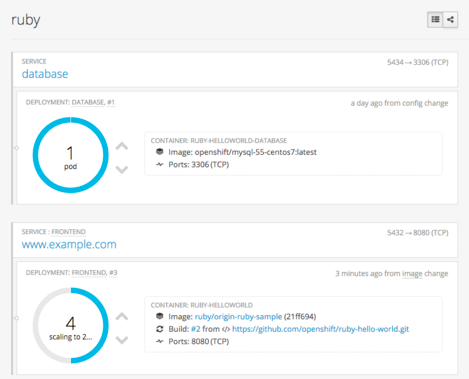
End users can now graphically see their deployed containers and choose to scale up or down their application instances from the web console.

Developers can be made more aware of how much room they have left in their pod's resource limit settings before a quota is enforced.

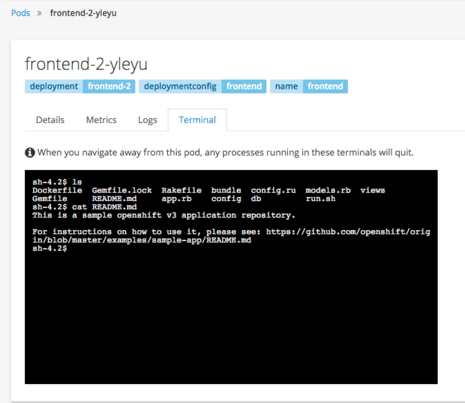
Developers can also remain in the web console and still gain terminal access to their deployed containers through a simply mouse click.

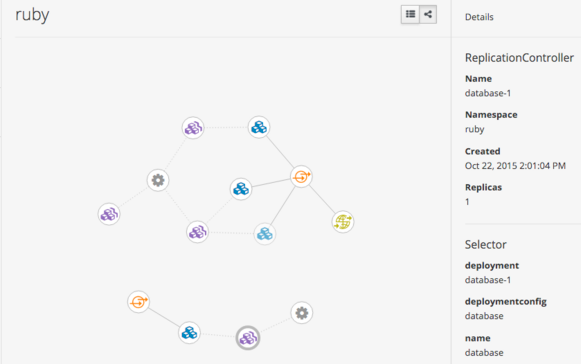
OpenShift makes it easy to deconstruct applications into container images, pods, services, and routes. As microservice applications grow and become more complex, it is often times beneficial to be able to view the relationship of those components.

Developers need a variety of log access to be successful when creating new application services.
- They need to be able to see a log stream realtime to their interface
- They need to be able to query the stream for common errors and issues
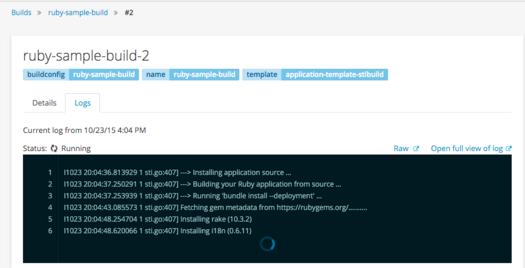
OpenShift 3.1 delivers on both of those requirements. We have taken the ability to stream logs from the pods to the command line and added an ability to stream them to the web console.

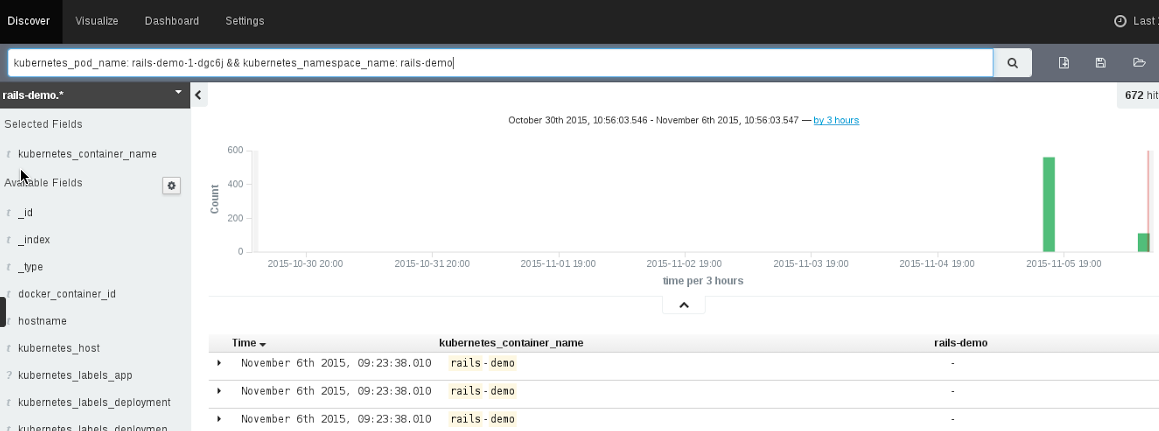
At the same time, we have added a logging framework to the solution. We have containerized and now provide Elasticsearch, Fluentd, and Kibana (the ELK stack with fluentd instead of logstash) and allow the platform administrator to deploy this log stack on OpenShift via provided templates. This results in the application owner being able log into Kibana in order to do analysis on his/her logs. OpenShift's configuration of Kibana allows for the application owner to see the log files related to only their application services.

OpenShift platform administrators can also use the logging framework to monitor and analyze the entire platform. This can be helpful when fulfilling auditing requirements.
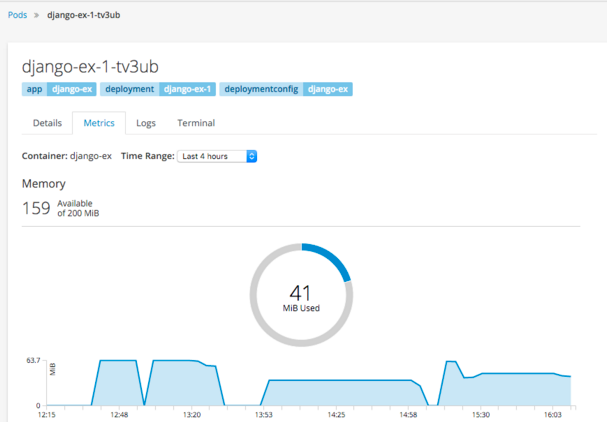
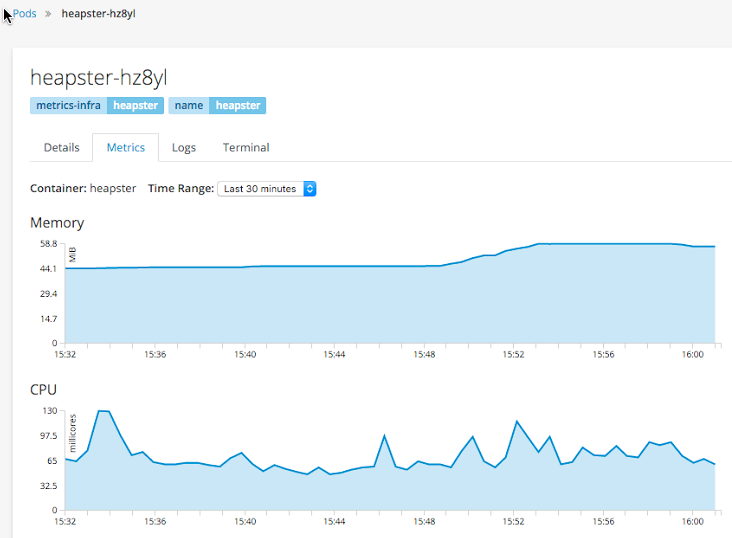
After developers gain access to logs, they often times will need to see metrics. Regardless of the runtime or application framework, they can now see CPU and MEM utilization for their deployed application instances. Should they be using java, we can also expose the JVM's JMX mbean information via the Jolokia agent. Lastly, if they are using JBoss Fuse, we are able to show their realtime camel routes.

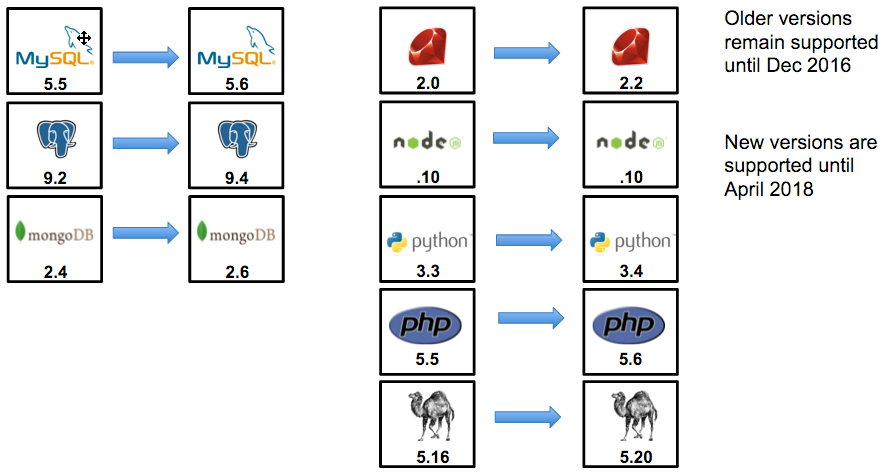
Red Hat provided runtimes and application frameworks have also been updated to offer developers more choice, while still off setting the cost of ownership for those applications back on Red Hat. We will help you get the most out of your support subscription for the platform's content by providing CVE, bug fixes, and tech support for these containerized solutions in a way that meshes well with your existing change management processes.

OpenShift 3.1 is also the release that the JBoss Middleware platform offers the following solutions:
- JBoss Web Server (tomcat) (JWS)
- JBoss Enterprise Application Server (EAP)
- JBoss A-MQ (AMQ)
- JBoss Business Rules Management (BRMS)
- JBoss Fuse (Fuse)
- JBoss Data Grid (JDG)
Specifically BRMS, Fuse, and JDG are new and will be released later in November for OpenShift 3.1. Application developers in organizations of any size need to be able to model, automate, measure, and improve their critical processes and policies. BRMS makes it possible with fully integrated business rules management and complex event processing.

Fuse is a lightweight Enterprise Service Bus (ESB) with an elastic footprint that supports integration with a massive catalog of service end points. On OpenShift 3.1, deploy Camel with or without Karaf while leveraging web console JMX and routing visualizations of large end point topologies. Developers should be able to arbitrarily add a data caching tier to their deployed services whenever they wish. JDG offers in-memory distributed databases designed for scalability and fast access to large volumes of data. The additional of these three JBoss solutions rounds out the OpenShift offering to allow developers an ability to design powerful open source application services.
As developers build out their application services, they will often times want to mix long running tasks (such as tomcat) with short lived tasks (such as a maintenance routine). Or maybe the short run task is an end point execution that is expected to run only until feedback is received. Whatever the need, OpenShift now allows users an ability to execute and schedule these short lives tasks through the job controller. Users can receive status back about the job (active, succeeded, failed). Users can execute the job immediately or on a schedule. Users can specify how many jobs should run concurrently if parallelism is desired. This is handled through the new 'oc scale job' command.
Operational Experience
It would not be devOps without operations. OpenShift 3.1 offers a number of enhancement for platform administrators.
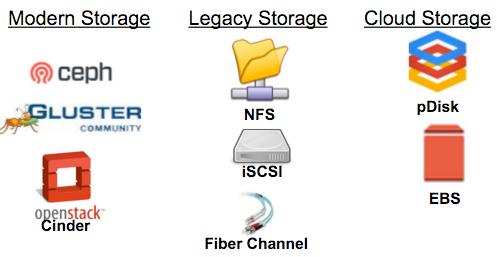
In order to support stateful applications, one must provide a large variety of storage backends. By doing so, the platform can be used for applications that require high IOPS, file based, or block based storage solutions. OpenShift 3.1 is excited to have qualified the following storage backends for use in application deployments. These remote persistent storage solutions allow the deployed containers on OpenShift to remain ephemeral while their application data is stored and maintained by the cluster in a persistent manner. Such a wide variety of storage at this high rate of automation allows OpenShift to tackle deploying data store components commonly found in bigdata or traditional application architectures.

Storage is only one IaaS service we are taking advantage of in OpenShift 3.1. The other is the network. OpenShift 3.1 offers better explainations and examples of incorporating existing datacenter routing layers into the solution. By looking that the F5® integration, one can easily apply the same design principles to any routing solution.
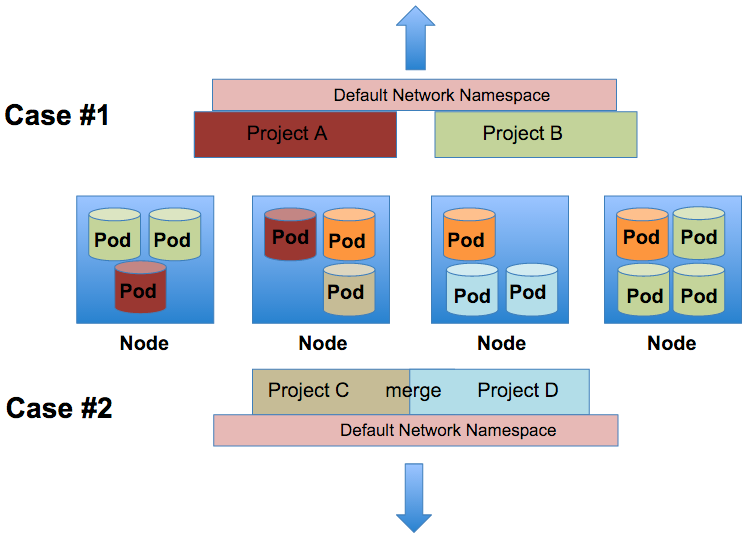
Another improvement in the area of networking is project based network isolation. Multi-tenant network isolation can work for two main use cases. A platform administrator can decide to turn on project level network isolation through the use of the multi-tentant network plugin. By enabling this plugin, the projects all become isolated through the use of VNIDs. OpenShift leverages an automated OpenvSwitch solution in order to provide an out of the box overlay network for pod to pod communication. These networking automation tasks are accomplished through OpenFlow rules. Each node is assigned a subnet of ip addresses and each OpenShift project creates a VXLAN overlay. This VXLAN is a layer 2 network implementation that runs over a layer 3 ECMP (IP) network. Each project within OpenShift receives a unique Virtual Network ID (VNID) for their VXLAN segment that identifies traffic from pods assigned to the project. Pods from different projects cannot send packets to or receive packets from pods and services of a different project.
- Case 1: Once enabled, all projects that exist (now and in the future) are isolated via VNIDs. There can be services that run on the platform (ie the routing tier) that can be told to run in a default network namespace with the VNID of 0. This allows such services to communicate with all the pods in the cluster.
- Case 2: A platform administrator can decide he/she would like to allow any number of projects to communication with each other. Thus merging the segmented VXLANs. This can be done via the 'oadm pod-network' command.

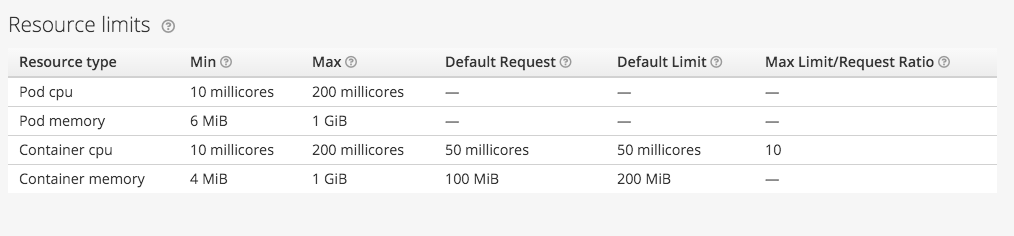
The connection between the cluster's resource awareness of workloads and how those resources are enforced out on the nodes is important. In this release, we allow you to set overcommitment ranges on CPU and MEM. Per your design decisions, you can allow containers to start small with possible higher threshold limits. By doing so, we can place a more dense number of containers on a node.

Speaking of CPU, we have also released in tech preview an ability to allow OpenShift to automatically scale horizontal application instances. OpenShift will check pod CPU usage every minute. That CurrentCPU value will be compared to a value you declare for the pod called TargetCPUConsumption. OpenShift will automatically add and remove pods within a MinCount and MaxCount range you have declared to insure the TargetCPUConsumption value is constant for the service deployment.
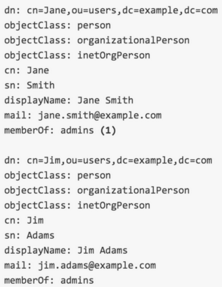
OpenShift offers a wide variety of ways to sync logical grouping of users found inside LDAP or Active Directory identity management solution to teams of user associated to OpenShift projects. 'oc sync-groups' allows for a number of include and exclude filters to be attached to it. Platform administrators can identify very granular parts of the identity tree or declare specific value key pairs.

A enhancement to the docker-storage command has been made to allow for someone to switch from a device mapper LVM for the node level docker image storage over to an overlayFS. OverlayFS is now supported in RHEL7.2 for linux container use cases. This particular union file system is performant when the same docker image lands on the same node in the cluster over and over again.
OpenShift's installation has been made user friendly. Users can choose to drive the embedded ansible playbooks through an question and answer shell experience or supply value key pairs to a documented configuration file for a hands free experience.
At the same time, OpenShift 3.1 offers highly available deployment configurations. OpenShift no longer requires the use of RHEL HA addons to accomplish this HA installation configuration. The OpenShift 3.1 API and proxy services have been redesigned to understand leader election. Job/Replication controllers and the scheduler are deployed with an active passive scenario in mind. The etcd data store for the cluster is automatically looking to be deployed in a sharded configuration. These changes allow for a simple, but powerful installation method that is repeatable across a number of IaaS layers (OpenStack, AWS, VMWare, Microsoft, etc). Should the IT team require a graphical installer, the runbook automation feature set found in CloudForms can be leveraged.
Red Hat has decided to allow OpenShift users an opportunity to leverage Red Hat CloudForms at no additional cost for the management and runbook automation of OpenShift nodes. Specifically, the CloudForms 4.0 release later this year has developed an OpenShift provider that allows platform administrators to:
- See aggregations and historical utilization of pods and nodes running in OpenShift
- See and incorporate event information from OpenShift into IaaS layer automations
- Follow or drill down from OpenShift components into a IaaS provider's information such as VMWare®, AWS®, Microsoft®, OpenStack, etc. This insight allow administrators to connect abstract containerized application errors to the underlining infrastructure.

Partner Eco-System
One of the best parts about transparently building on open container formats and kubernetes has been the out pouring of ISV, VAR/SI, and customer collaboration.
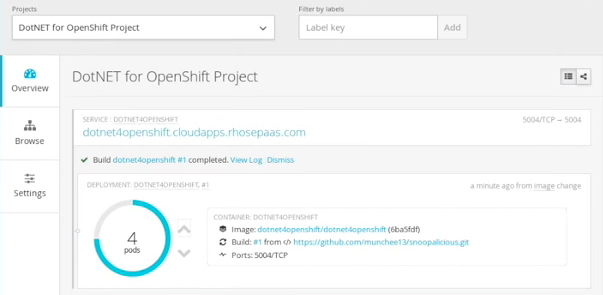
Earlier this month, Microsoft and Red Hat announced that .NET will be officially supported on RHEL. On the same day, OpenShift released a preview of how easy it is for use to deliver .NET services in a docker container through the source to image assembly factory found in OpenShift.

At the same time, OpenShift Enterprise customers can mix and match their OpenShift node subscriptions for use inside their datacenters or out on Azure in a supported manner. Similarly we have had strong collaborations with overlay network providers such as Nuage, developer tool solutions such as CloudBees, and application performance partners such as New Relic. The OpenShift 3 platform has resulted in a global upswell of innovation that comes from being in a open source community with over 150 active organizations.
OpenShift 3.1 was built for a generation of users who are under incredible pressure to find tomorrow's next great idea, who are still responsible for the current revenue generating application deployments of today, and who desire a platform that will allow them to build without prejudices. OpenShift 3.1 was built for you.
OpenShift 3.1 will be available for download from the Red Hat registry and global file shares in the next few days.
About the author

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
More like this
Browse by channel

Automation
The latest on IT automation that spans tech, teams, and environments

Artificial intelligence
Explore the platforms and partners building a faster path for AI

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
Explore how we reduce risks across environments and technologies

Edge computing
Updates on the solutions that simplify infrastructure at the edge

Infrastructure
Stay up to date on the world’s leading enterprise Linux platform

Applications
The latest on our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Developer resources
- Customer support
- Red Hat value calculator
- Red Hat Ecosystem Catalog
- Find a partner
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit