
At Red Hat we don’t just do open source and write software. We help our clients adopt good practices, spread open source culture, and adopt technology in the right way.
This post will explore less technical and more “big picture” concepts. When we (Red Hat Professional Services) come on-site to help to deploy OpenShift (Enterprise-ready Kubernetes distribution) we work with the customer to determine what kind of journey they will experience while onboarding and the challenges they may encounter in the future.
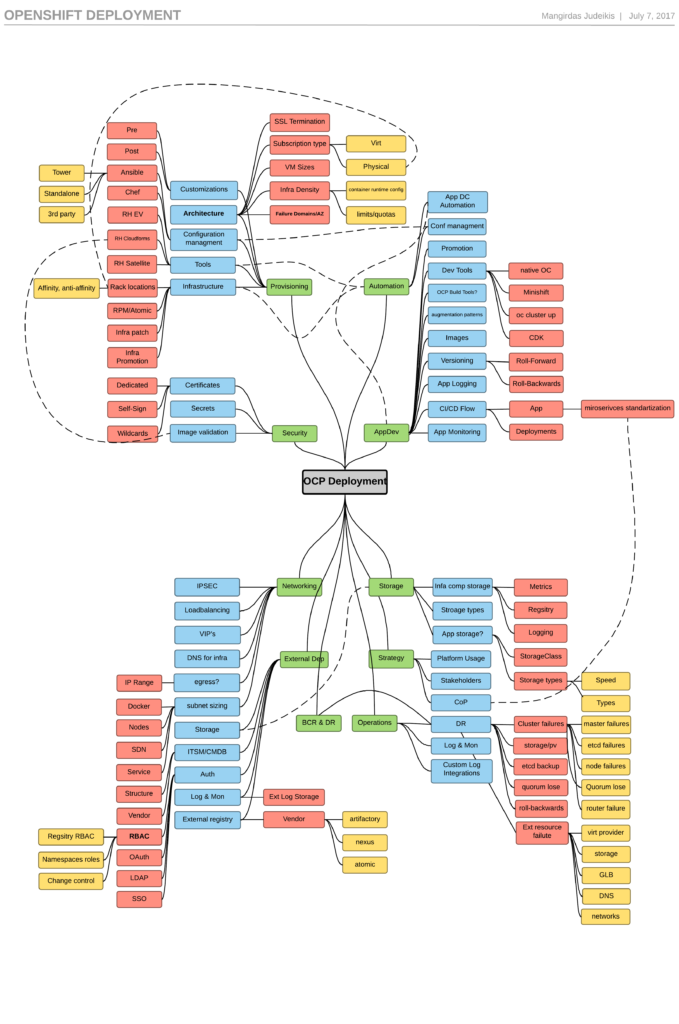
For this purpose, I created a small MindMap to help visualize most of the dependencies that exist when building highly distributed platform. There is much more to this, and this visualization is being updated even as you read this article, but it’s a good start.
All dependencies are split into 10 categories:
- Strategy
- Storage
- Operations
- BCR & DR
- AppDev
- Security
- Automation
- Networks
- Provisioning
- External dependencies
Each of these contain multiple sub-areas to consider. So let's go through them one by one.
TL:DR: Even if you are familiar with this topic, you may find the MindMap valuable. If you want more, I have provided insights for each and every block. Click to enlarge the image or view at https://github.com/mangirdaz/ocp-mindmap.

1. Strategy
Your strategy should be one of the first things you think about before beginning the journey of adopting a new platform. You need to know who will be using this platform you are building. Who are the stakeholders, and finally, who is responsible for it? Determining stakeholders is often the easiest part of building the strategy. Establishing a Community of Practices (CoP) will help create a strategy and directions. A well-thought-out and maintained CoP can help you use the power of your own organization to drive progress towards the “right solution.” Solutions delivered behind closed doors tend to miss what an organization needs.
One other area where you will need a strategy is “microservices standardization." Before putting services on the new platform, it is highly recommended to have certain standards defined. The challenge here is that old world standards do not apply in this new world. Trying to “copy paste” something you already know might not work as well as you might expect. Consider doing some research on using CoP.
2. Storage
Storage, or persistence, is a key consideration to plan for if you want a successful platform. And you don’t just need simple storage but highly-scalable storage. You will need storage for internal platform components like logging, metrics, and the container registry. Some of those might not be required if you chose to go with a different implementation of those the solutions (object storage, messaging based logging) based on where you will be building this. But you will not be able to eliminate the need for storage completely. As soon as we start speaking “persistence” we mean storage. Start thinking about how you will do it, who will provide it for you, and what flavors (SSD, Magnetic, SAN, NAS, etc.) of storage you will have.
3. Operations
The operations section is very tightly connected to next section of this post. Operations mainly consist of 2 areas: Business as Usual (BAU) and unplanned activities (BCR & DR). I’ll cover the last one separately in the next section.
BAU operations will consist of things like egress router configurations, platform maintenance, patching, scheduling rules creations, platform management, and proactive reactions to the events happening on the platform. For all this, you will need a very good logging and monitoring stack available. Without those you will be blind; and being blind in a highly distributed system is much much worse than in a “standalone servers” infrastructure because things might go from bad to worse very fast. For example, if you lose capacity, your containers will get rescheduled (assuming you don't have autoscaling, and even if you do, you might start getting very big bills). Rescheduling in the current configuration = bigger density, which means there is a big chance you will soon get into a rolling failure scenario.
So defining standard runbooks for your operations, creating dashboards, and making sure you know your environment is one of the most important things when it comes to operations.
4. BCR & DR
I’ve split Business Continuity & Resilience (BCR) and Disaster Recovery (DR) from operations because it is a very big concern. Even before serving production traffic, I recommended you already know your “failure domains” and how to recover if any of those domains fail. For example, you need a plan for if you lose quorum in your distributed reliable key-value store cluster (etcd in the case of OpenShift/Kubernetes) or know what would happen if an external DNS or storage provider fails. There could be multiple different scenarios, which will be different in different environments. Some of the internal/external dependencies will have less or more mature offerings, depending on which type of organization you are in.
5. AppDev
You need to think about your developers too. Some organizations forget that the platform will be used mostly by developers. And only developers know how they want to run things in a platform. Despite the fact that you will have a lot of tools already in place, you might want to standardize on patterns and blueprints. For example, you should consider:
- How will application developers monitor their applications and node performance?
- How will they do promotion and deployment?
- How CI/CD pipelines (existing ones and new ones) will integrate with the platform.
- How will you be promoting images from the across the environment?
- What about configuration promotion?
- And finally, what development tools your developers will be using?
Developer experience is very important. Get this right, and your platform will be used. Get it wrong, and nobody will want to use it.
6. Automation
This particular area has many relationships to other areas. You will need automation for your applications (CI/CD tools), image testing, promotions, etc. Additionally, your infrastructure should be treated the same as your apps— automation everywhere. For this, you might use configuration management tools or rely only on deployment tools. But if you start building from the beginning with the idea of automation, it will get you where you want to be faster, even if it looks slower in the beginning.
7. Networking
You need to think about how you will be accessing your applications, egress and ingress traffic, and how your load balancers will be configured. Determine if you will run active-passive or active-active, and how you will load balance all your stack. Do you want your containers to be “ the first citizen in the network” or will you rely on SDN abstraction? How will DNS be handled? Do you want to do Mutual SSL all over the place (and do you really really need it)? How big will your cluster be in 2-5 years? How many containers will you run on one node? All these questions will define your network design for the platform.
8. Security
Despite the fact that the platform was built with security in mind, you still will have a lot of open questions. For example, how you are managing your secrets (passwords, certificates) and how will rotate them? How will you expose your application to the outside world? And finally, and most importantly, how will you validate images you are running? Image scanning and lifecycle is key when running multitenancy, microservice-based applications.
9. Provisioning
Provisioning is very broad and highly connected to how you do these things in your organization:
- Configuration management: Which one will you use, and how it will play with the tools the platform supports? As soon as you chose one, what tooling comes with it? What additional tools will you need? Will you need Red Hat Satellite for subscription and infra lifecycle management? And CloudForms for insights, capacity, and proactive management? What is the visualization provider and its capabilities?
- Infrastructure itself: Do you use containerized deployments or package/RPM-based? How does this connect to your organization patching strategies? For example, if you are a full RPM-based organization, and you chose a containerized/OSTree based platform, will your ops know how to lifecycle those?
- And finally, what customization will you need to do for the platform (pre, post actions) to make it compliant and custom for your needs?
10. External dependencies
You will have a lot of these, so make sure you know how resilient they are and what SLAs they provide. A few external dependencies would be:
- Logging and monitoring: Where do you send your logs for archiving? Do you have any external logging and monitoring solution you need to integrate with? Will you provide metadata too?
- Storage: How will you use it? Is it fast enough? What about input/output operations per second (IOPS)? What will happen if it goes down or gets filled?
- Container registry: If you plan to run a globally distributed set of clusters, how will you make sure you have a consistent view of your images? Do you have the need to storage container images externally? If so, what format?
- Authentication & authorization: How will you authenticate your users and applications? What is the preferred auth provider? How you do your Role Based Access Control (RBAC) based on your auth provider?
- ITSM/CMDB: Do you need to register your apps on any configuration management database? How this will be automated (or will an automated solution even work here?). What do you consider a change?
11. Architecture
The thing which should be one of the first I saved for the last. As soon as you know where you want to go (strategy), you need to start thinking about wider architecture, such as an infrastructure density, datacenters, and availability zones. Most of the areas already covered are associated with the architecture of the platform itself. You need to make the right choices in the beginning, as distributed platforms like Openshift/Kubernetes are hard to modify (the core of it) when it is built and in use by hundreds, or even thousands, of applications. If you get networking wrong it is not impossible to change it later. If you do not accommodate the ability of your external dependencies to scale with your platform, you will create bottlenecks.
All these are high level points what you need to think about if you chose to go on this journey. And let's be clear about one thing: Public cloud does not solve all these questions. It's just a different conversation. It may look hard and not worth it. But the final result—having full-cloud agnostic, horizontally and vertically scalable self-service infrastructure—will make developers happy.
About the author

{kind=link}
More like this
Browse by channel

Automation
The latest on IT automation that spans tech, teams, and environments

Artificial intelligence
Explore the platforms and partners building a faster path for AI

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
Explore how we reduce risks across environments and technologies

Edge computing
Updates on the solutions that simplify infrastructure at the edge

Infrastructure
Stay up to date on the world’s leading enterprise Linux platform

Applications
The latest on our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Developer resources
- Customer support
- Red Hat value calculator
- Red Hat Ecosystem Catalog
- Find a partner
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit