
Note: This scenario assumes you already have an OpenShift 4 cluster or have followed the instructions in the Deploying OpenShift Container Storage 4 to OpenShift 4 Blog to set up an OpenShift Container Platform 4.2.14+ cluster using OpenShift Container Storage 4.
1. Overview
Jenkins is one of the most important development infrastructure components, but can we make Jenkins pipelines run faster? Using OpenShift Container Storage we can speed up the build time of applications by using persistent storage to save the stateful data of dependencies and libraries, for example, that are needed during compilation.
1.1. In this blog you will learn how to:
- Create a Jenkins template that uses OpenShift Container Storage 4 persistent storage.
- Implement a BuildConfig for the JAX-RS project.
- Use Jenkins’s PodTemplate in the BuildConfig to create Jenkins (Maven) agent Pods that will use OpenShift Container Storage 4 persistent storage.
- How to run a simple build and measure the performance.
- How OpenShift Container Storage 4 helps shorten the build time.
- How to run the demo in a multi Jenkins environment simulating large engineering organization with many groups/projects using different Jenkins instances.
- How to do all this from the command line.
2. Prerequisites:
- Make sure you have a running OCP cluster. If you do not have a running OCP cluster, follow the instructions in the Deploying OpenShift Container Storage 4 to OpenShift 4 Blog to set up an OpenShift Container Platform 4.2.14+ cluster using OpenShift Container Storage 4.
- A copy of this git repository.
- NOTE: The scripts in this lab will work on Linux (various distributions) and MacOS. They have not been tested on any Windows OS.
- Please git clone our repository and once cloned, you’ll find all the scripts needed in the ocs4jenkins directory:
git clone https://github.com/red-hat-storage/ocs-training.git
3. Deploying Jenkins
3.1. Jenkins introduction
Jenkins is a free and open source automation server. The gist of Jenkins is very simple: it helps the software development process by doing things that a developer would normally do manually. It’s typically used to manage build and test processes, where lots of scripts and little bits of software need to be run in succession in order to produce working binaries, containers or virtual machine images. In that sense, it matches the concept of continuous delivery (CD) perfectly.
Here, Jenkins is a server-based system that runs as a servlet in a containerized environment. It can interact with all major version control tools and can automate builds using tools like Maven, Ant and SBT.
Because of this level of integration with version control software, builds can easily be triggered by an action such as a "commit" in git. Builds can also be started via a daily/hourly cron job or even by simply requesting a build URL.
3.2. Our Jenkins demo
In our demo/example, we are going to use a Jenkins pipeline to build the openshift-tasks project to demonstrate how to implement a JAX-RS service. We are going to create an OpenShift project that will hold a Jenkins Pod (that also uses OpenShift Container Storage 4 persistent storage) and then when we start our build, the Jenkins master Pod is going to create a Maven Pod to actually run the build. That Maven Pod will use OpenShift Container Platform 4 for persistent storage.
The actual code we compile is not important for the demo, we are just utilizing the build stages to show how OpenShift Container Storage 4 can save significant amounts of build time. The pipeline has well-defined stages:
- Create the Maven Pod.
- Clone the code.
- Build the artifact (including getting all dependencies).
- End the build.
Note: Pipelines usually have more stages, including at least one testing stage, but we are skipping these stages here.
Figure 1. Jenkins pipeline demo components
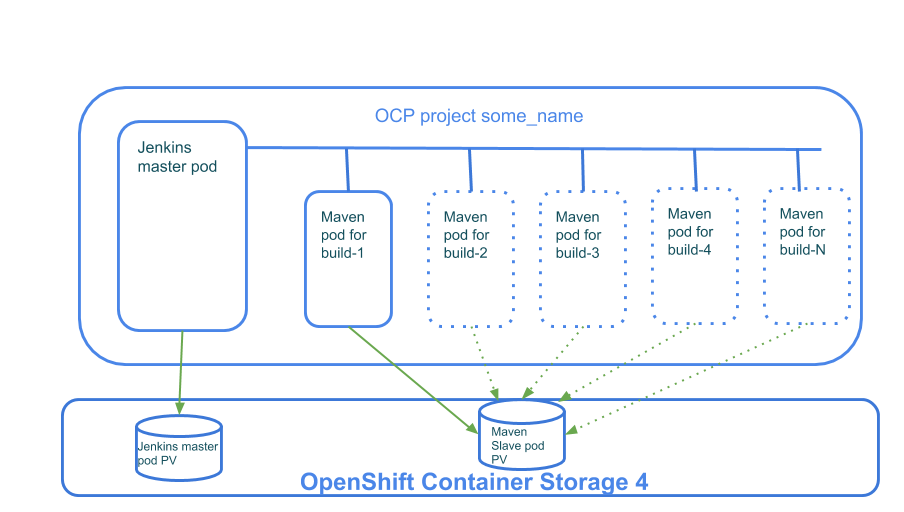

3.3. Creating a Jenkins template that uses OpenShift Container Storage 4
OCP4 comes preconfigured with two Jenkins templates to use:
oc get templates -n openshift -o custom-columns=NAME:.metadata.name|grep -i jenkins
Example output:
jenkins-ephemeral
Jenkins-persistent
We are going to create a new template based on the jenkins-persistent template. To do so, we are going to run the create_ocs_jenkins_template script.
The script parameters (CSI_DRIVER, PV_SIZE and NEW_TEMPLATE_NAME) are self explanatory; you can edit the script and change them but remember that other scripts in this lab might use the default value of NEW_TEMPLATE_NAME. The script will perform the following tasks:
- Change the name of the template (so it can co-exists with the one we copied from).
- Add the storage class (sc) we want to use in the template (the jenkins-persistent template just uses the default storage class in OCP).
- Add/change the size of the PV we want for the Jenkins pod.
- Add some Jenkins Java pod creation parameters to speed up new containers creation.
- Run the "oc create" command and then create the new template
Run the create_ocs_jenkins_template script:
$ bash create_ocs_jenkins_template
After running the script, you should see another jenkins template:
oc get templates -n openshift -o custom-columns=NAME:.metadata.name|grep -i jenkins
Example output:
jenkins-ephemeral
jenkins-persistent
Jenkins-persistent-ocs
The last jenkins template jenkins-persistent-ocs is the one that we are going to use.
3.4. Creating our project
Now that we have a Jenkins OpenShift Container Storage 4 template, we can deploy Jenkins and use the deploy_jenkins bash script to:
- Create a project.
- Create a persistent volume claim that will be used for all our builds.
- Create a Jenkins server Pod (using the template from previous step).
- Create the Jenkins pipeline build configuration (as a BuildConfig) for our openshift-tasks project.
The script accepts two variables from the command line: the OpenShift project name you want to use and the persistent storage driver you want to use (in our case ocs-storagecluster-ceph-rbd).
The real "magic" takes place at the BuildConfig object, so before running the script, let’s take a look:
1 kind: "BuildConfig"
2 apiVersion: "v1"
3 metadata:
4 name: "jax-rs-build"
5 spec:
6 strategy:
7 type: JenkinsPipeline
8 jenkinsPipelineStrategy:
9 jenkinsfile: |-
10 *PodTemplate*(label: 'maven-s',
11 cloud: 'openshift',
12 inheritFrom: 'maven',
13 name: 'maven-s',
14 volumes: [persistentVolumeClaim(mountPath: '/home/jenkins/.m2', claimName: 'dependencies', readOnly: false) ]
15 ) {
16 node("maven-s") {
17 stage('Source Checkout') {
18 git url: "https://github.com/sagyvolkov/sagy-openshift-tasks.git"
19 script {
20 def pom = readMavenPom file: 'pom.xml'
21 def version = pom.version
22 }
23 }
24 // Using Maven build the war file
25 stage('Build JAX-RS') {
26 echo "Building war file"
27 sh "mvn clean package -DskipTests=true"
28 }
29 }
30 }
So the pipeline is very simple, we create a Maven Pod (based on the OpenShift Container Platform Maven default image, line #10), git clone our code (line #18), and then create the artifact using Maven (line #27).
The "PodTemplate" section is where we attached the persistent volume that was created in the previous step in the script (the claim is called "dependencies").
The importance of keeping the same claim is simple: for each build, when we build the artifact, we need to download all the dependencies in order to compile the code. Since these dependencies don’t really change most of the time for the same code, we use OpenShift Container Storage 4 persistent storage to keep the data persistent for each build, thus making any Maven build that follows the first build, up to 90% faster.
After explaining all of this, let’s run the script:
bash deploy_jenkins myjenkins-1 ocs-storagecluster-ceph-rbd
3.5. Running the build and looking at results
The oc command to run a build is very simple and it is literally oc start-build, however we are going to use the bash script run_builds to not only run this command for you, but also run the build 5 times in a sequential manner, measuring the duration of each run, and outputting this data into a log file per run. The script accepts two variables, the OpenShift project name where you created the Jenkins pod (and of course the BuildConfig and persistent volume), and a directory to place the outputs.
bash run_builds myjenkins-1 myjenkins-1
If we look at the newly created myjenkins-1 directory, it should have 10 files (2 files for each of the 5 runs of the build):
The files that match -- are the output of the Jenkins build runs.
The files starting with "log-" will hold the build duration data. A quick grep sample of the results will show similar results to these:
cat myjenkins-1/log-myjenkins-1-jax-rs-build-*|grep 'Total time'
Example output:
[INFO] Total time: 01:39 min
[INFO] Total time: 5.337 s
[INFO] Total time: 3.510 s
[INFO] Total time: 3.258 s
[INFO] Total time: 2.930 s
What we are "grepping" for is the total time it took for the actual maven Pod to run the build. Or, to be precise, the mvn clean package -DskipTests=true command. As you can see, the first build in this example took 99 seconds, while all the consecutive builds took less than 5 seconds. The reason for this is that the dependencies are downloaded for the first build and then reused again and again for any other build that follows.
It is important to note that this is a fairly small project/code that we’re using and bigger projects/code, will have an even greater impact on the maven commands as the dependencies will most likely be much larger.
Also important to note, if we would have used ephemeral storage for our Maven Pods, each of the 5 builds would have taken roughly 99 seconds. If we do some simple math, using ephemeral storage would have taken us roughly 500 seconds to run 5 builds versus the roughly 115 seconds if we are using OpenShift 4 persistent storage for the Maven pods!
3.6. Running our demo in a multi-tenant environment
In real-life scenarios with Jenkins in the Kubernetes/DevOps world, there are usually several Jenkins servers running. It could be there’s a Jenkins server per development team, or maybe a Jenkins server per engineering group (Dev, QE, Support, Professional services and so on). It could be that a developer is working on several projects that require different versions of Jenkins or Jenkins plugins. As you can see, the notion of having many Jenkins servers running on a single OpenShift cluster using some sort of software defined storage is very real.
To simulate a multi-Jenkins server environment, we are going to use the previous scripts (deploy_jenkins and run_builds), however, we’re going to "wrap" these two scripts with scripts that will create a multi-Jenkins server environment. The init_and_deploy_jenkins-parallel bash script variables are easy to understand. The script deploys NUMBER_OF_PROJECTS instances of Jenkins, with each project that holds a single Jenkins server named with the prefix of PROJECT_PREFIX. The script is doing the creation in batches of the DEPLOY_INCREMENT variable just to avoid any kind of resource issues during the Pod creation part.
To run the script:
bash init_and_deploy_jenkins-parallel
Once we have our Jenkins servers/Pods running, we can run our previous demo in parallel on all the Jenkins servers. For that we will use the run_builds-parallel script, which basically runs the run_builds script for the number of projects we created previously (remember, each OCP project hold a single Jenkins server). The variable NUMBER_OF_PROJECTS needs to match the same number from the init_and_deploy_jenkins-parallel script.
The script also creates a separate directory per project to store the output from the runs.
The script accepts one variable - which is a name for the run - so all other project directories output will be created under this RUN_NAME directory. To run the script:
bash run_builds-parallel running_60_jenkins
Once all runs are done (should take roughly 10 minutes), you can simply run the calculate_results script to go through all directories and calculate all the averages per run.
This script has some variables that need to match previous scripts, NUMBER_OF_PROJECTS, PROJECT_PREFIX, BUILD_CONFIG and NUMBER_OF_BUILDS must match the variables from all 4 previous scripts. The script also accepts the RUN_NAME variable, the same one we used in the run_builds-parallel script.
Note: Depending on where you are running the scripts (remotely from your laptop or a node/pod inside the lab) and how good did the Kubernetes scheduler "spread" the Jenkins and maven pods, the run of 60 Jenkins pods doing 5 builds in parallel can take between 10 to 20 minutes, so you might want to change the number of projects running in parallel to a smaller number if you don’t want to wait.
bash calculate_results running_60_jenkins
The output should be similar to this in the sense that the average of the first build will be significantly higher than the rest (these numbers are in seconds):
bash calculate_results testing_60
Example output:
Average for build 1: 91.2667
Average for build 2: 8.248
Average for build 3: 5.41643
Average for build 4: 5.64875
Average for build 5: 4.7366
For the curious mind: Check to see if the Kubernetes scheduler has done a good job at distributing the 60 Jenkins pods:
$ oc get pods -o wide --all-namespaces|grep jenkins |grep -vi deploy|grep 1/1|awk '{print $8}'|sort|uniq -c
Resources and Feedback
To find out more about OpenShift Container Storage or to take a test drive, visit https://www.openshift.com/products/container-storage/.
If you would like to learn more about what the OpenShift Container Storage team is up to or provide feedback on any of the new 4.2 features, take this brief 3-minute survey.
About the author

Sagy Volkov is a former performance engineer in ScaleIO, he initiated the performance engineering group and the ScaleIO enterprise advocates group, and architected the ScaleIO storage appliance reporting to the CTO/founder of ScaleIO. He is now with Red Hat as a storage performance instigator concentrating on application performance (mainly database and CI/CD pipelines) and application resiliency on Rook/Ceph.
He has spoke previously in Cloud Native Storage day (CNS), DevConf 2020, EMC World and the Red Hat booth in KubeCon.
Browse by channel

Automation
The latest on IT automation that spans tech, teams, and environments

Artificial intelligence
Explore the platforms and partners building a faster path for AI

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
Explore how we reduce risks across environments and technologies

Edge computing
Updates on the solutions that simplify infrastructure at the edge

Infrastructure
Stay up to date on the world’s leading enterprise Linux platform

Applications
The latest on our solutions to the toughest application challenges

Original shows
Entertaining stories from the makers and leaders in enterprise tech
Products
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Cloud services
- See all products
Tools
- Training and certification
- My account
- Developer resources
- Customer support
- Red Hat value calculator
- Red Hat Ecosystem Catalog
- Find a partner
Try, buy, & sell
Communicate
About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
Select a language
Red Hat legal and privacy links
- About Red Hat
- Jobs
- Events
- Locations
- Contact Red Hat
- Red Hat Blog
- Diversity, equity, and inclusion
- Cool Stuff Store
- Red Hat Summit