
Red Hat blog
Today for my 30 day challenge, I decided to learn how to use the Stanford CoreNLP Java API to perform sentiment analysis. A few days ago, I also wrote about how you can do sentiment analysis in Python using TextBlob API. I have developed an application which gives you sentiments in the tweets for a given set of keywords. Let's look at the application to understand what it does.
Application
The demo application is running on OpenShift http://sentiments-t20.rhcloud.com/. It has two functionalities:
- The first functionality is that if you give it a list of twitter search terms it will show you sentiments in latest 20 tweets for the given search term. You have to enable this by checking the checkbox as shown below. The positive tweets are shown in green and negative tweets in red.
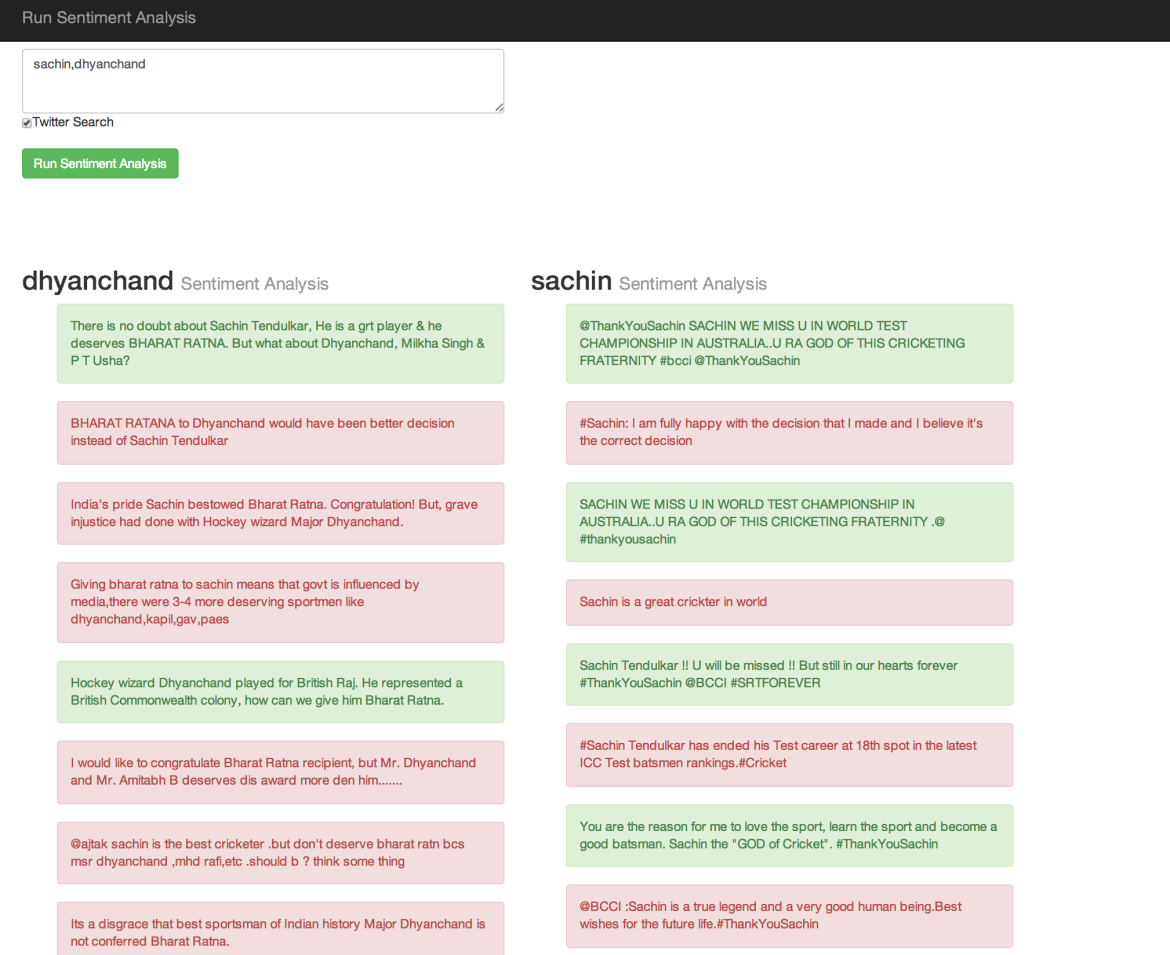
-
The second functionality is to do sentiment analysis on some text as shown below.
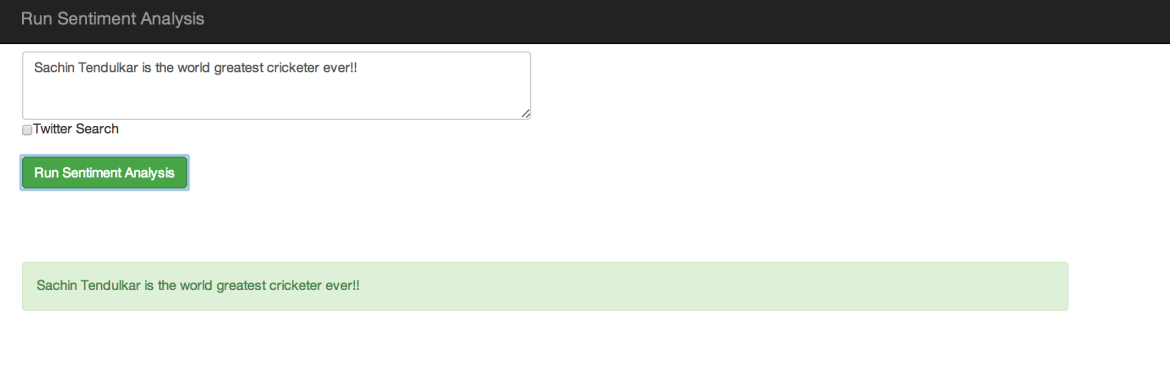


What is Stanford CoreNLP?
Stanford CoreNLP is a Java natural language analysis library. Stanford CoreNLP integrates all our NLP tools, including the part-of-speech (POS) tagger, the named entity recognizer (NER), the parser, the coreference resolution system, and the sentiment analysis tools, and provides model files for analysis of English.
Prerequisite
- Basic Java knowledge is required. Install the latest Java Development Kit (JDK) on your operating system. You can either install OpenJDK 7 or Oracle JDK 7. OpenShift support OpenJDK 6 and 7.
-
Download the Stanford CoreNLP package from the official website.
-
Sign up for an OpenShift Account. It is completely free and Red Hat gives every user three free Gears on which to run your applications. At the time of this writing, the combined resources allocated for each user is 1.5 GB of memory and 3 GB of disk space.
-
Install the rhc client tool on your machine. RHC is a ruby gem so you need to have ruby 1.8.7 or above on your machine. To install rhc:
sudo gem install rhc
If you already have one, make sure it is the latest one. To update your rhc, execute the command shown below.sudo gem update rhc
For additional assistance setting up the rhc command-line tool, see the following page: https://openshift.redhat.com/community/developers/rhc-client-tools-install -
Setup your OpenShift account using
rhc setupcommand. This command will help you create a namespace and upload your ssh keys to OpenShift server.
Github Repository
The code for today's demo application is available on github: day20-stanford-sentiment-analysis-demo.
SentimentsApp up and running in under two minutes
We will start by creating the demo application. The name of the application is sentimentsapp.
$ rhc create-app sentimentsapp jbosseap --from-code=https://github.com/shekhargulati/day20-stanford-sentiment-analysis-demo.git
If you have access to medium gears then you can use following command.
$ rhc create-app sentimentsapp jbosseap -g medium --from-code=https://github.com/shekhargulati/day20-stanford-sentiment-analysis-demo.git
This will create an application container for us, called a gear, and setup all of the required SELinux policies and cgroup configuration. OpenShift will also setup a private git repository for us using the code from github application repository. Then it will clone the repository to the local system. Finally, OpenShift will propagate the DNS to the outside world. The application is accessible at http://sentimentsapp-{domain-name}.rhcloud.com/. Replace {domain-name} with your own unique OpenShift domain name (also sometimes called a namespace).
The application also requires four environment variables corresponding to a twitter application. Create a new twitter application by going to https://dev.twitter.com/apps/new. Then, create the four environment variables as shown below.
$ rhc env set TWITTER_OAUTH_ACCESS_TOKEN=<please enter value> -a sentimentsapp
$ rhc env set TWITTER_OAUTH_ACCESS_TOKEN_SECRET=<please enter value> -a sentimentsapp
$rhc env set TWITTER_OAUTH_CONSUMER_KEY=<please enter value> -a sentimentsapp
$rhc env set TWITTER_OAUTH_CONSUMER_SECRET=<please enter value> -a sentimentsapp
Now restart the application to make sure the server can read the environment variables.
$ rhc restart-app --app sentimentsapp
Under the hood
We started by adding maven dependencies for stanford-corenlp and twitter4j in pom.xml. Please use 3.3.0 version of stanford-corenlp as the sentiment analysis API is added to 3.3.0 version.
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-corenlp</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.twitter4j</groupId>
<artifactId>twitter4j-core</artifactId>
<version>[3.0,)</version>
</dependency>
The twitter4j dependency is required for twitter search.
Then we updated the maven project to Java 7 by updating a couple of properties in the pom.xml file:
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
Now update the Maven project Right click > Maven > Update Project.
Enable CDI
We used CDI for dependency injection. CDI or Context and Dependency injection is a Java EE 6 specification which enables dependency injection in a Java EE 6 project. CDI defines type-safe dependency injection mechanism for Java EE. Almost any POJO can be injected as a CDI bean.
The beans.xml file is added to src/main/webapp/WEB-INF folder to enable CDI.
<beans xmlns="http://java.sun.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/beans_1_0.xsd">
</beans>
Search twitter for keywords
Next we created a new class TwitterSearch which uses Twitter4J API to search twitter for keywords. The API requires twitter application configuration parameters. Instead of hard coding the values, we are using environment variables to get the values.
import java.util.Collections;
import java.util.List;
import twitter4j.Query;
import twitter4j.QueryResult;
import twitter4j.Status;
import twitter4j.Twitter;
import twitter4j.TwitterException;
import twitter4j.TwitterFactory;
import twitter4j.conf.ConfigurationBuilder;
public class TwitterSearch {
public List<Status> search(String keyword) {
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true).setOAuthConsumerKey(System.getenv("TWITTER_OAUTH_CONSUMER_KEY"))
.setOAuthConsumerSecret(System.getenv("TWITTER_OAUTH_CONSUMER_SECRET"))
.setOAuthAccessToken(System.getenv("TWITTER_OAUTH_ACCESS_TOKEN"))
.setOAuthAccessTokenSecret(System.getenv("TWITTER_OAUTH_ACCESS_TOKEN_SECRET"));
TwitterFactory tf = new TwitterFactory(cb.build());
Twitter twitter = tf.getInstance();
Query query = new Query(keyword + " -filter:retweets -filter:links -filter:replies -filter:images");
query.setCount(20);
query.setLocale("en");
query.setLang("en");;
try {
QueryResult queryResult = twitter.search(query);
return queryResult.getTweets();
} catch (TwitterException e) {
// ignore
e.printStackTrace();
}
return Collections.emptyList();
}
}
In the code shown above, we filter the twitter search results to make sure no retweet, or tweet with links, or tweet with images are returned. The reason for this is to make sure that we get tweets which have text.
SentimentAnalyzer
Next we created a class called SentimentAnalyzer which run sentiment analysis on a single tweet.
public class SentimentAnalyzer {
public TweetWithSentiment findSentiment(String line) {
Properties props = new Properties();
props.setProperty("annotators", "tokenize, ssplit, parse, sentiment");
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
int mainSentiment = 0;
if (line != null && line.length() > 0) {
int longest = 0;
Annotation annotation = pipeline.process(line);
for (CoreMap sentence : annotation.get(CoreAnnotations.SentencesAnnotation.class)) {
Tree tree = sentence.get(SentimentCoreAnnotations.AnnotatedTree.class);
int sentiment = RNNCoreAnnotations.getPredictedClass(tree);
String partText = sentence.toString();
if (partText.length() > longest) {
mainSentiment = sentiment;
longest = partText.length();
}
}
}
if (mainSentiment == 2 || mainSentiment > 4 || mainSentiment < 0) {
return null;
}
TweetWithSentiment tweetWithSentiment = new TweetWithSentiment(line, toCss(mainSentiment));
return tweetWithSentiment;
}
}
We copied the englishPCFG.ser.gz and sentiment.ser.gz models to src/main/resources/edu/stanford/nlp/models/lexparser and src/main/resources/edu/stanford/nlp/models/sentiment folders.
Created SentimentsResource
Finally, we created the JAX-RS resource class.
public class SentimentsResource {
@Inject
private SentimentAnalyzer sentimentAnalyzer;
@Inject
private TwitterSearch twitterSearch;
@GET
@Produces(value = MediaType.APPLICATION_JSON)
public List<Result> sentiments(@QueryParam("searchKeywords") String searchKeywords) {
List<Result> results = new ArrayList<>();
if (searchKeywords == null || searchKeywords.length() == 0) {
return results;
}
Set<String> keywords = new HashSet<>();
for (String keyword : searchKeywords.split(",")) {
keywords.add(keyword.trim().toLowerCase());
}
if (keywords.size() > 3) {
keywords = new HashSet<>(new ArrayList<>(keywords).subList(0, 3));
}
for (String keyword : keywords) {
List<Status> statuses = twitterSearch.search(keyword);
System.out.println("Found statuses ... " + statuses.size());
List<TweetWithSentiment> sentiments = new ArrayList<>();
for (Status status : statuses) {
TweetWithSentiment tweetWithSentiment = sentimentAnalyzer.findSentiment(status.getText());
if (tweetWithSentiment != null) {
sentiments.add(tweetWithSentiment);
}
}
Result result = new Result(keyword, sentiments);
results.add(result);
}
return results;
}
}
This code does the following:
- Checks if searchkeywords is not null and not empty. Then it split the searchKeywords into an array. It only considers three search terms.
- For every search term it finds the tweets and performs sentiment analysis.
- Finally it returns the results list to the user.
That's it for today. Keep giving feedback.
Next Steps
- Sign up for OpenShift Online and try this out yourself
- Promote and show off your awesome app in the OpenShift Application Gallery today.